本章的主题是列表,与向量一样列表也是典型的最基本的一类线性结构,但是列表结构与向量结构在几乎所有的方面都是对称的、互补的,因此它的特点也十分的鲜明。本文主要介绍列表的接口与实现,无序列表和有序列表。
1.接口与实现
1.1.从静态到动态
根据是否修改数据结构,所有操作大致分为两类方式:
- 静态:仅读取,数据的内容及组成一般不变:get、search
- 动态:需写入,数据结构的局部或整体将改变:insert、remove
与操作方式相对应地,数据元素的存储于组织方式也分为两种
静态:数据空间整体创建或销毁
数据元素的物理存储次序与其逻辑次序严格一致
可支持高效的静态操作
比如向量,元素的物理地址与其逻辑次序线性对应
动态:为各数据元素动态地分配和回收的物理空间
逻辑上相邻的元素记录彼此的物理地址
形成一个整体可支持高效的动态操作
这里的代表就是我们这一章的主题:列表
1.2.从向量到列表
列表(list)是采用动态存储策略的典型结构
- 其中的元素称作节点(node)
- 各节点通过指针或引用彼此联接,构成一个逻辑上的线性序列:$L=\{a_0,a_1,\dots,a_{n-1}\}$
相邻节点彼此互称前驱(predecessor)或后继(successor)
- 前驱或后继若存在,则必然唯一
- 一个序列中的第一个元素称为首节点(没有前驱),最后一个元素称为末节点(没有后继)
以下图为例,对于任何一个列表而言,首先都有一个入口的位置,所有的元素确实可以从入口开始沿着它们之间的引用,依次地从相对的前驱转向后继以及后继的后继,直到最终的末节点。虽然在逻辑上它们是这样的一个排列的次序,但是在物理上却远远不是。但是这样不妨碍它们定义并且实现这样的一个次序,比如说从某一个位置出发,我们可以找到它的物理位置并且访问它,接下来可以顺着它的后继的引用找到它的后继,以及再顺着后继的引用找到后继的后继,诸如此类直到最终抵达末节点,从而退出这个列表。
1.3.从秩到位置
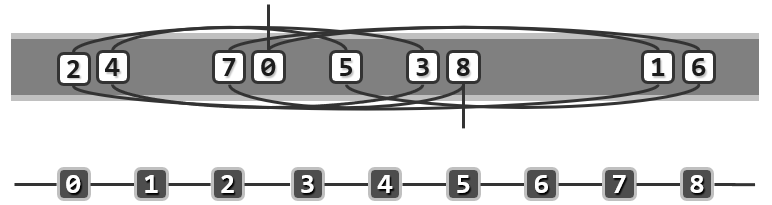
向量支持循秩访问(call-by-rank)的方式,根据数据元素的秩,可在$O(1)$时间内直接确定其物理地址,
V[i] 的物理地址 = V + i × s,s为单个单元占用的空间量
既然同属线性序列,列表固然也可通过秩找到对应的元素
为找到秩为
i的元素,须从头(尾)端出发,沿引用前进(后退)i步然而因为成本过高,此时的循秩访问已不合时宜
以平均分布为例,单次访问的期望复杂度为$(n+1)/2=O(n)$
因此,应改用循位置访问(call-by-position)的方式访问列表元素,也就是说,应转而利用结点之间的相互引用,找到特定的节点
1.4.实现
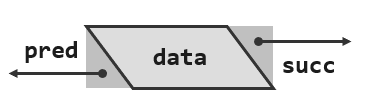
1.4.1列表节点:ADT接口
- 作为列表的基本元素,列表节点首先需要独立地“封装”实现。为此,可设置并约定若干基本的操作接口

1.4.2.列表节点:ListNode模板类
1 |
|
1.4.3列表:ADT接口
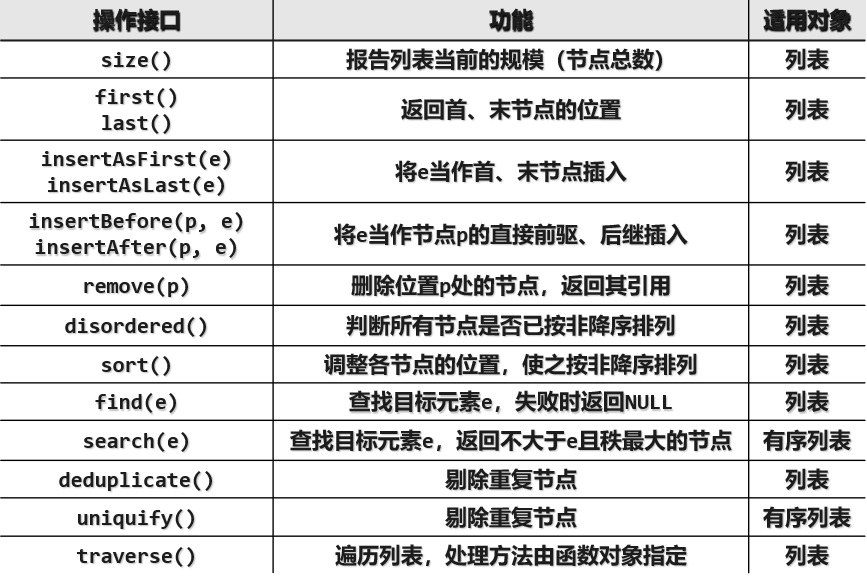
在给出列表结构的具体实现之前,首先定义一组它所应该提供的操作接口,仔细看会发现它的接口的形式以及对应的功能与第二章中所学过的向量Vector结构颇为类似,这里逐一再展开了,在后边相应的各节将对它们的功能和实现再做详细的介绍。
1.4.4.列表:List模板类
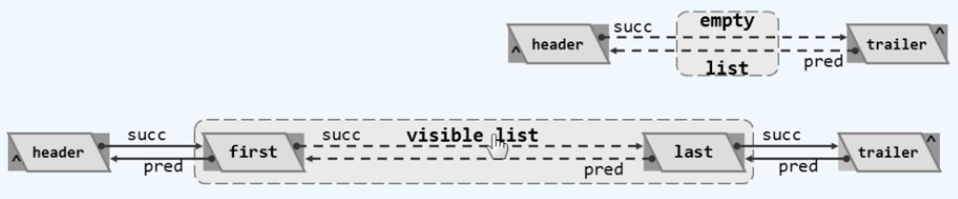
接下来介绍列表也就是List这种模板类的具体定义,首先要引入刚才所实现的列表节点类,可以看到List这种模板类也是分为三个层次,其中private 私有的层次与向量类似,记录的都是那些对外不可见的部分,具体包括规模、引入两个哨兵节点。另外也包括一些内部的功能函数,以及刚才我们所定义的那些对外开放的标准ADT接口。
1 |
|
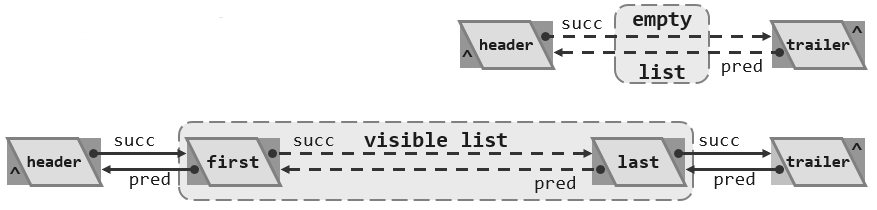
这样的一个宏观结构可以用下面的图来表示,任何一个List结构都会拥有一个叫作header,以及另一个叫作trailer的哨兵节点,header和trailer对外是不可见的,当然我们后面会看到它们的作用非常巨大。而对外可见的部分主要是介乎header和trailer之间的这样的一系列的元素,其中如果存在的话,第一个元素也就是firstNode,我们称作首元素,而最后一个last我们称作末元素。那么相应的也把名字规范一下,称header叫作头元素,称trailer是尾元素。

- 等效地,头、首、末和尾这四个节点的“ 秩 ”可以分别理解为是等于-1、0、n-1以及n。
那么它们之间的联系是:头节点和尾节点是与生俱来的,而且二者并不相同,first和last并不见得不相同,甚至不能保证它们存在,但是对外而言first、last是可见的,而trailer和header这两个哨兵都是invisible不可见的。当然从秩的角度来看一个长度为n的列表中,头、首、末和尾这四个节点的秩可以分别理解为是等于-1、0、n-1以及n。
1.4.5.构造
如此定义的一个列表结构可以按照这样的过程来创建:首先要为header和trailer分别地分配一个节点使它们真实的存在,接下来要将它们的后继以及前驱引用分别指向对方,从而实现这样一个互联的效果。当然逻辑上看
这个时候对外可见的那个列表实际上是没有任何元素的,对应的就是一个空列表。而在接下来的几节里会介绍如何实现在其中插入一些元素,以及再插入一些元素,也可能时不常地从中删除或者是修改某一个元素。总而言之这个列表将有可能会包含一些实在的、对外可见的节点,我们在后面几节再来看这些操作是如何具体实现的。
1 | template <typename T> void List<T>::init() { //列表初始化,在创建列表对象时统一调用 |
2.无序列表
2.1.秩到位置
这一节讨论无序列表的相关算法,首先关心的一个问题是既然列表和向量同属于线性的序列结构那么是否可以继续沿用向量那种,十分便捷也是我们十分习惯的循序秩访问的方式呢?具体说来,对于任何一个名字叫L的列表,每当我们指定其中一个合法的秩r,都可以以这样的一个形式来直接引用并且访问到对应的这个节点。
答案是可以的,因为我们可以仿照向量的做法对下标操作符进行适当的重载,具体的方法如下:
1 | template < typename T> //重载下标操作符,以通过秩直接访问列表节点(虽方便,效率低,需慎用) |
由此也可以看出这个算法的复杂度是取决于所指定的那个秩r的,即$O(r)$,这个是十分低下的。实际上这种用法虽然很方便,但是我们只能偶尔为之而不能常用。估算它的平均性能为$O(n)$,需要线性的时间,这样一个性能,无论如何我们都是无法接受的。
2.2.查找
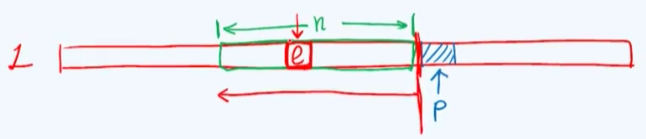
接下来考虑无序列表的查找算法,这里将这个算法的接口语义定义为在当前的列表L中以位置为p的某一个特定节点为基准,在它的n个真前驱中(不包括它自己在内的n个前驱中)找到某个可能存在的数值为特定值e的节点。
仿照向量的查找算法我们从p这个位置出发,从后向前将每个节点逐一取出并与目标元素进行比对,一旦发现相等也就是命中,即可停止。
这样一个过程可以准确地描述为下面的代码:
1 | template < typename T> //在无序列表内节点p(可能是trailer)的n个真前驱中,找到等于e的最后者 |
注意无论是成功的情况所返回的p,还是失败时返回的NULL,都是我们此前所定义的一个节点位置Position。还要注意一种特殊的情况,即目标节点e不仅存在而且可能有多个,那么在这时根据这个算法,它会首先停止于相对而言最靠后的那个节点,因为这正是我们的语义所要求的一个细节。
那么在最坏的情况下,当然这个算法必须一直迭代到最末尾这个位置,累计的宽度是n,所以相应的复杂度也就是最坏情况下$O(n)$。

还需要留意的是,我们这里的三个参数的次序find(T const& e, int n, Posi(T) p),为什么这里将n放在p的前端呢?实际上这是为了让我们更方便地了解这个算法的功能语义,当使用find(e, n ,p)这样一个方式来调用这个接口的时候,你就很容易理解它是在p的n个前驱中去进行查找。换而言之我们完全可以重载另一个接口find(e, p, n),它的不同之处就在于p和n的位置恰好交换,这就意味着是在p的n个后继中去查找特定的某一个元素。
2.3.插入
本节以insertBefore(前插入)为例介绍列表插入功能的实现,所谓的insert Before就是在当前的列表中以某个位置p为基准,在它的前方也就是作为它的前驱插入一个新的节点,而且这个节点的数值应该是我们指定的e。可以看到实际上它是通过转而由p作为一个节点的对象所支持的一个叫作insert as predecessor这样一个接口来实现的。
1 | template < typename T> Posi(T) List<T>::insertBefore(Posi(t) p, T const& e){ |
insertAsPred首先生成一个节点,它的数值为e,这个节点的前驱就是节点this的前驱,而这个新生成出来的节点的后继恰好就是this。所以Posi(T) x = new ListNode(e, pred, this);这样一句不仅创建了一个数值为e的节点,而且完成了这个节点到当前这个列表的正确的连接。
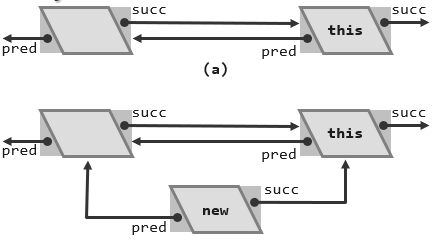
接下来做进一步的调整,也就是既然新的这个节点已经以节点this作为后继,那么当前节点this也就应该以新的这个节点作为前驱。反之新的这个节点既然以原来的那个前驱为前驱,那么原来的这个前驱也就应该以新的这个节点为后继,至此完成了新节点的插入操作。(类似于Cpp基础6中的链表的创建过程)
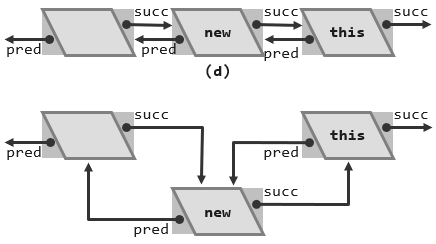
需要注意的是这样一种操作只是在局部进行,只牵涉到局部的三个节点,与其它的节点没有关系,它的复杂度是常数的,而这一点与向量是迥然不同的(向量插入元素后,原位置其后的元素要整体后移)。
考虑一些特殊的情况,比如说如果当前这个节点this是首节点,以至于它的前驱根本就不存在,那么这个时候这种操作难道不会出问题吗?其实是不会出问题的,因为我们在此前设立过哨兵,即便当前这个节点是首节点,它的前驱在内部依然是存在的,也就是header,那么这个时候的这种操作依然是安全的。
2.4.基于复制的构造
有的时候我们也需要以某个已有的列表为蓝本,通过复制来创建一个新的列表,这样的过程可以由下面的代码来实现。
1 | template < typename T> //列表内部方法:复制列表中自位置p起的n项 |
解读下这个算法:可见这里被复制的节点范围是从某一个列表的位置p开始随后地连续n个节点,因此首先我们创建一个空的列表,它只包含内部的头尾哨兵节点,不包含任何实质的节点。接下来我们不断地将当前这个p处
所指的那个节点的元素取出来,把它作为当前列表的末节点插入其中,每做完这样一个新节点的引入,我们都会将注意力转向当前这个节点的后继,如此往复直到这个区间中的所有n个节点,都被复制过来。
那么其中的insertAsLast怎么来实现呢?回顾我们所有对外可见的最后那个节点叫作last 即末节点,但是我们还同样配备了一个哨兵节点叫作trailer。所以所谓的insertAsLast其实就是insertBefore trailer。

2.5.删除
接下来介绍如何从列表中删除指定的节点。可以通过下面的代码来实现。
1 | template <typename T> |
首先我们需要将这个节点的数据域取出作一备份,以便在最终能够顺利地将它返回,而删除节点之后整个列表在这个局部的拓扑连接关系的调整则是由第4、5行来完成的,通过下面的图便于理解一下这个过程。
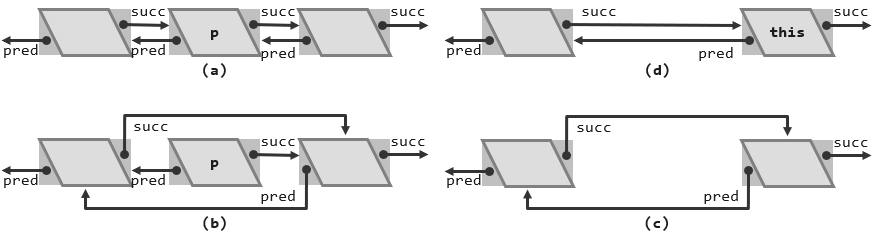
p->pred->succ = p->succ的效果是将p现在的后继当作p现在的前驱的后继,这样等同于将后继的这个引用直接跳过了p。而p->succ->pred = p->pred的过程以及效果与前一句完全对称,具体来说就是将p现在的前驱作为p的现在后继的前驱。这样两句的实质的作用可以理解为是将这个局部的后继引用,以及前驱的引用都跳过节点p,也就是说 p可以认为与原来的列表已经在拓扑上隔离开了。所以当我们将p直接地通过delete操作删除并归还系统之后就实现了指定节点p的删除。
整个这个过程只牵涉到局部的三个节点其余的节点没有任何的影响,由此也可以确认删除算法的复杂度与插入算法一样,都是常数的。
2.6.析构
如何销毁一个已有的列表呢?整个过程分为两步,首先要将对外可见的所有节点逐一删除,当所有对外可见的节点都被删除之后,再将内部的两个哨兵也就是header以及trailer给释放了。
所以整个这个算法分为两级:析构方法首先调用一个名为clear的函数,将所有的可见节点删除,接下来再将header和trailer删除掉,那么clear的实质的工作也就是反复的删除header的后继。
1 | template <typename T> List<T>::~List() { //列表析构 |
2.7.唯一化
本节介绍列表的唯一化问题,即如何将列表中可能存在的重复元素剔除掉。在接下来要介绍的这个算法中,我们始终将整个列表视作由三部分组成,这个前缀部分作为这个算法的一条不变性,已经能够保证不包含任何重复的节点,而我们当前所要考察的就是接下来的这个节点p,当然此时可能还存在一个非空后缀。
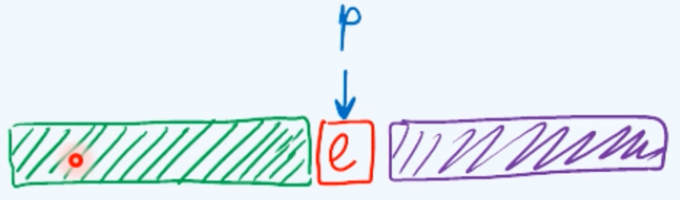
这个算法的关键部分是如果当前那个节点的数值为e,就以e为目标在前缀中对它进行查找,无论查找成功与否
我们都可以将问题的规模,有效地降低至少一个单位,具体的算法可以实现为这样一段代码:
1 | template <typename T> int List<T>::deduplicate() { //剔除无序列表中的重复节点 |
解读一下这段代码:首先是处理平凡情况,确保这个列表中至少包含两个节点,接下来这一步可以认为是初始化,可以看到p最初的时候是指向首节点,即这时的前缀实际上可以认为是空的,所以不变性自然也就满足。接下来算法的主体部分是这个循环,可以看到每一次我们都将p中所存的那个元素在以p为基准的r个真前驱中查找。
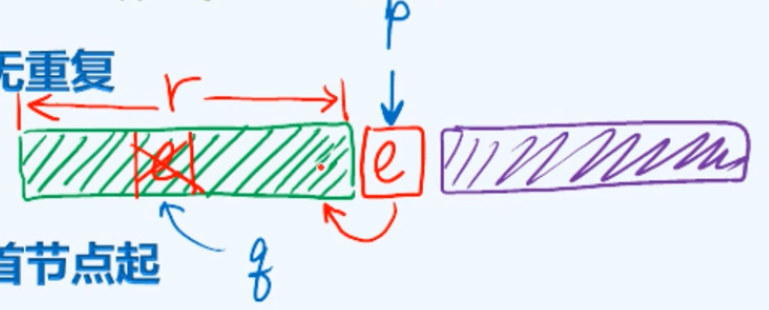
在前缀中进行查找无非两种情况:一种就是find操作返回了一个非空的元素,它的数值当然就等于e,这是就把q删除掉了;否则如果q是一个null,那就意味着查找失败,即在这样的一个前缀中根本就不存在语义相同的元素,所以在这之后p这个节点可以归入到前缀中去,使得这个前缀拓展一个单位,在这种情况下就可以将r加1,即前缀的长度增加一个单位,同时p转入它的后继元素继续迭代,直到抵达哨兵trailer也就意味着整个列表全部扫描并且处理完毕。
3.有序列表
本节介绍有序列表,我们假设其中的元素不仅可以比较大小而且已经按照这种大小关系有序地排列。在这样的一个条件下很多问题都存在更加高效的解法。
3.1.唯一化:原理
以唯一化问题为例,回顾有序向量的唯一化可以比无序向量的唯一化更快地完成,那么有序列表的唯一化是否也能够比无序列表的唯一化完成地更快呢?在介绍出具体的算法之前,我们先来分析一下算法的思路。
回顾在有序向量的去重算法中,曾经介绍过这样一个事实:在任何一个有序的序列中,如果存在重复元素,那么每一组重复元素必然会彼此紧邻地排列成一个又一个的分组,每一个分组都由彼此相同的一组元素构成。而唯一化的任务可以等效地理解成是从每一组中挑选出一个代表,而将其余的元素都剔除掉。于是仿照有序向量的唯一化算法也可以得到一个迭代式的算法。
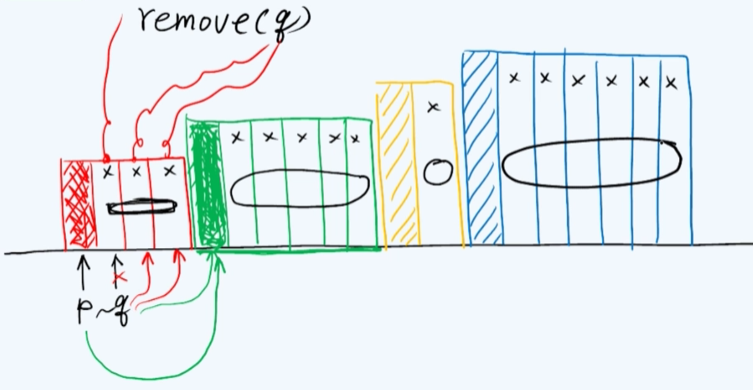
具体来讲每一次迭代我们都将注意力关注于当前以p指示的那个节点,同时还要考虑p的直接后继q,在经过一次比对之后如果发现p和q相等,就可以将后者剔除掉,这个可以通过列表所提供的remove标准接口来实现。此后q将指向新的后继节点。同样地在接下来的一步迭代中,依然会发现q与p相等,所以可以继续将它删除。
在某一步接下来的迭代中情况可能发生变化,即首次发现一个与p不同的节点,这时就预示着一个新的区段出现了,作为这个新的区段的首节点,我们将保留这个节点。而为了这个算法能够继续计算下去,不妨将p由原来的位置转向这个新发现的不同的节点(图中p由红色转向绿色)。可以看到经过这样一轮迭代之后,刚才相同的一组元素中,除了第一个其余的后继都被删除掉了。
3.2.唯一化:实现
上小节的算法思路可以实现为下面一段具体的代码:
1 | template <typename T> int List<T>::uniquify() { //成批剔除重复元素,效率更高 |
解读一下这段代码:首先是处理平凡的情况,即要确保这个列表至少包含两个元素。我们所关注的总是当前节点p,这个节点从首节点开始,同时还有另一个辅助的引用q指向p的后继。以下是一个循环,每一次我们都令q指向p的直接后继,随后将二者作一比对,如果相同就调用remove接口将q删除掉;反过来 一旦遇到一个与p不同的后继节点,那么就意味着抵达了下一个区段的首节点,这个时候我们就可以直接将注意力转向这个下一个区段的首节点也就是q。此后发生的情况将与刚才那样一轮迭代完全相同,迭代持续进行直到最终q试图越过边界,这时整个算法也就宣告结束。
整个算法过程主体的复杂度来源是while,可以看到每经过一步迭代p都会转入一个新的节点,所以整个迭代
至多经过线性步就会停止,所有这个算法的时间复杂度为$O(n)$,这相对于无序列表也是一个很大的改进。
3.3.查找
有序列表的去重操作相对于无序列表而言可以更快地进行,那么其它的操作呢?比如我们最最关心的查找呢?
有序的列表的查找操作可以由下面一段代码实现:
1 | template < typename T> //在有序列表内节点p的n个(真)前驱中,找到不大于e的最后者 |
我们发现这个算法与无序列表居然没有太多的差异,同样它在最好情况下也是常数,比如在开始的位置就发现命中目标;反过来最坏也可能多达$O(n)$,即一直查找到最后才得出是否命中的结论。在整个查找范围也就是p之前的n个前驱中,每一个元素对应的查找成本将呈算数级数趋势变化,总体而言是线性的。
这样的结论多少会令人失望,因为尽管我们这里已经将列表中的元素按顺序进行了重新组织,但是查找的效率居然没有实质的改进。这并不是我们实现不当,而根本的原因在于列表的循位置访问这种方式。这种访问方式与向量的循秩访问有着本质的差异。
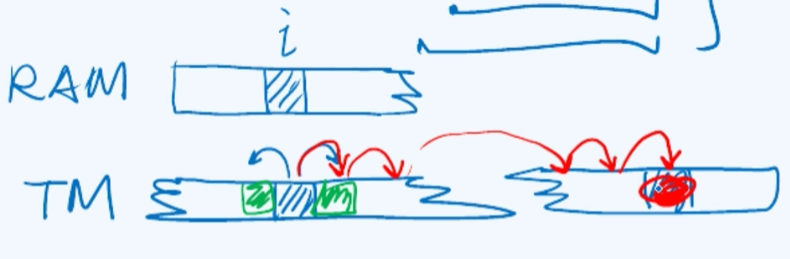
Vector这种结构在访问数据的时候,所依据的实际上是秩rank,而列表结构所依据的是位置position。在此前
所介绍过的计算模型,实际上对于RAM模型来说,它所对应的其实就是循秩访问的方式。对于RAM模型来说每给出一个编号i,都可以在$O(1)$的时间内找到对应的寄存器,读取其中的数值或者对其进行修改。
再来看图灵机模型,虽然“纸带”长度无限,但在任何时候我们所能够操纵的只是其中某一个特定的单元,而且更重要的是在接下来只可能向左或者向右移动一格。如果的确需要访问一个相距很远的单元,我们将不得不亦步亦趋地逐步地通过多步的迭代才能够抵达目标,这正是我call-by-position,而不是RAM那种call-by-rank。