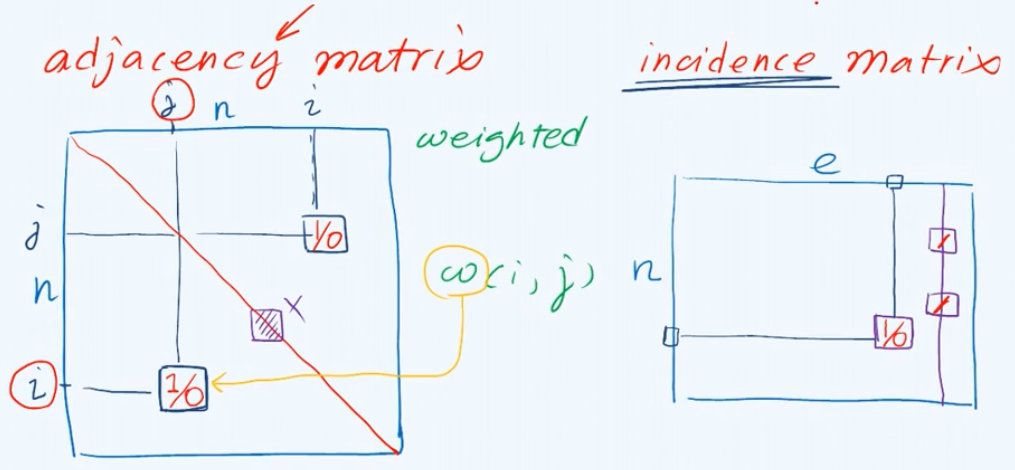
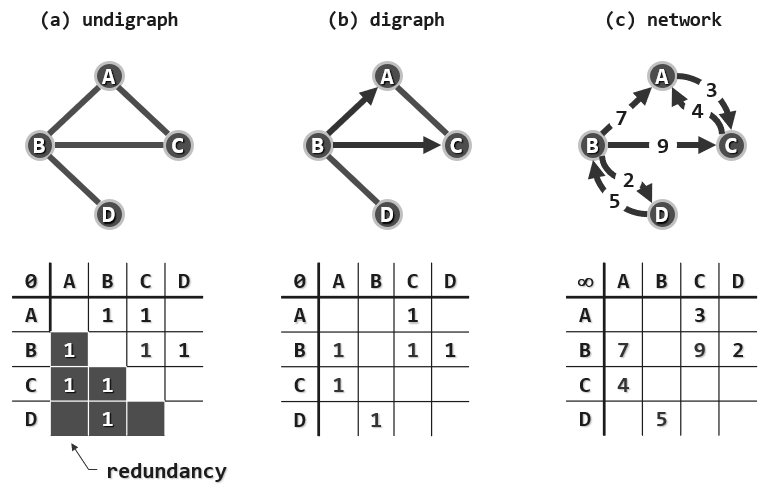
template <typename Te> structEdge {//边对象(为简化起见,并未严格封装) Te data; //数据 int weight; //权重 EStatus status; //(如上五种)状态 Edge ( Te const& d, int w ) : data ( d ), weight ( w ), status ( UNDETERMINED ) {} //构造 };
// 顶点的基本操作:查询第i个顶点(0 <= i < n) virtual Tv& vertex( int i ){ return V[i].data; } //数据 virtualintinDegree( int i ){ return V[i].inDegree; } //入度 virtualintoutDegree( int i ){ return V[i].outDegree; } //出度 virtual VStatus& status( int i ){ return V[i].status; } //状态 virtualint& dTime( int i ){ return V[i].dTime; } //时间标签dTime virtualint& fTime( int i ){ return V[i].fTime; } //时间标签fTime virtualint& parent( int i ){ return V[i].parent; } //在遍历树中的父亲 virtualint& priority( int i ){ return V[i].priority; } //在遍历树中的优先级数
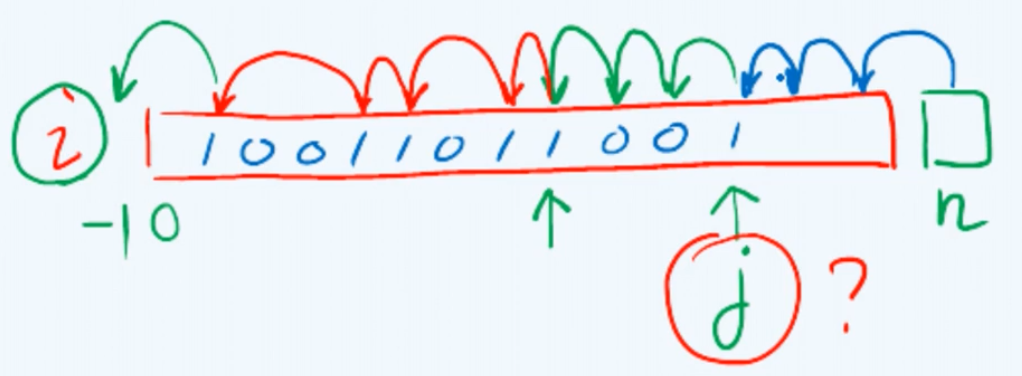
对于任意顶点i,如何枚举其所有的邻接顶点neighbor?为此首先需要实现一个名为nextNbr的接口,它的功能语义是如果我们现在已经枚举到顶点i的编号为 j 的邻居,那么它将返回接下来的下一个邻居。与顶点 i 潜在的可以相邻的点,无非就是它在邻接矩阵中所对应的那一行中数值为1的单元,对应于与i邻接的一个顶点。而第一个有效的邻居是通过firstNbr接口实现,它调用了nextNbr,将顶点n(并不实际存在)作为上一个有效的邻居。
1 2 3 4 5 6 7
virtualintnextNbr( int i, int j ){//相对于顶点j的下一邻接顶点 while ( ( -1 < j ) && ( !exists ( i, --j ) ) ); //逆向线性试探,O(n) return j; } //改用邻接表可提高至O(1 + outDegree(i)) virtualintfirstNbr( int i ){ return nextNbr ( i, n ); } //首个邻接顶点
2.6.边操作
同样地,利用邻接矩阵我们也可以便捷地实现很多边的基本操作
1 2 3 4 5 6 7
// 边的确认操作 virtualboolexists( int i, int j )//边(i, j)是否存在 { return ( 0 <= i ) && ( i < n ) && ( 0 <= j ) && ( j < n ) && E[i][j] != NULL; } // 边的基本操作:查询顶点i与j之间的联边(0 <= i, j < n且exists(i, j)) virtual EStatus & status( int i, int j ){ return E[i][j]->status; } //边(i, j)的状态 virtual Te& edge( int i, int j ){ return E[i][j]->data; } //边(i, j)的数据 virtualint& weight( int i, int j ){ return E[i][j]->weight; } //边(i, j)的权重
virtualvoidinsert( Te const& edge, int w, int i, int j ){ //插入权重为w的边e = (i, j) if ( exists ( i, j ) ) return; //确保该边尚不存在 E[i][j] = new Edge<Te> ( edge, w ); //创建新边 e++; //更新边计数 V[i].outDegree++; //更新关联顶点i的出度 V[j].inDegree++; //更新关联顶点i的入数 }
边删除:
不妨假设从顶点 i 通往顶点 j 之间存在一条边,因此在邻接矩阵中对应的那一项就非空,而且这一项将指向一个对应的边记录。为了删除这条边,只需将这条边对应的记录释放并且归还给系统,然后令在邻接矩阵中对应于这一项的引用指向空。
1 2 3 4 5 6 7 8
virtual Te remove( int i, int j ){ //删除顶点i和j之间的联边(exists(i, j)) Te eBak = edge ( i, j ); delete E[i][j]; E[i][j] = NULL; //备份后删除边记录 e--; V[i].outDegree--; V[j].inDegree--; //更新边计数与关联顶点的度数 return eBak; //返回被删除边的信息 }