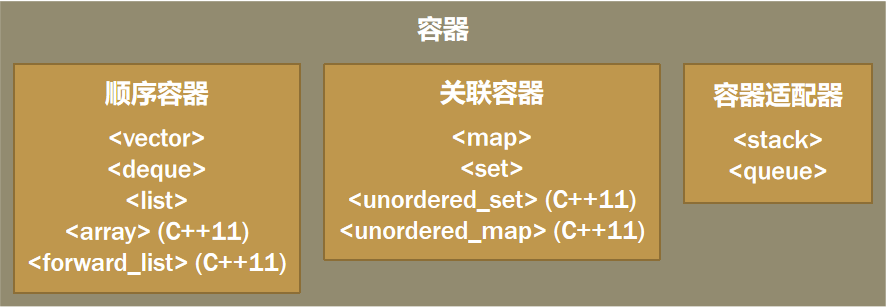
容器是可容纳各种数据类型的数据结构
- 包括顺序容器和关联容器
- 还有一类不提供真正的用于存储元素的数据结构实现,称作容器适配器
- 容器适配器不支持迭代器,由使用者选择合适的底层数据结构
1.顺序容器
在顺序容器中,元素的插入位置与元素的值无关:
vector(声明于 < vector>)顺序表:实现了一个动态数组,可以在常数时间内完成随机存取元素,可以自动调整大小,在尾端增删元素时具有较佳的性能
array(C++11 中新增,声明于 < array>)
顺序表:封装了一个静态数组,只能在初始化时指定大小deque(声明于 < deque>)
双端队列:实现了一个动态数组,可以在常数时间内完成随机存取元素,可以快速地在数组的头尾两端增删元素list(声明于 < list>)
双向链表:不支持随机存取,但在任何位置增删元素都能在常数时间完成forward_list( C++11 中新增,声明于)
单向链表:list类的单链表版,去掉了一些操作
1.1. vector
vector 实现了一个动态数组,在实例化 vector 模板类时,需要在 <> 内指定容器中元素的具体类型,元素可以是基本数据类型,也可以是自定义的类。vector 可以在常数时间内完成随机存取元素,支持随机访问迭代器。
vector 可以自动调整大小,在尾端增删元素时具有较佳的性能,可以视为在常数时间内完成;在其他位置增删元素时较慢,与具体的位置有关。所有 STL 算法都能对 vector 操作。
构造 vector 对象时,需要声明具体的数据类型:可以指定一个初始长度,但之后还可以通过其他成员函数改变长度;还可以传入两个参数,分别指定初始长度和元素的初始值。也可以根据一个已有的数组来构造 vector 对象,传入的两个参数分别表示数组的起始和终止位置,是个左闭右开的区间。
1 |
|
访问vector中的元素时,可以通过迭代器来访问或修改元素,也可以通过 [] 或 at() 成员函数访问或修改元素。
1 | int main() { |
vector 在数组尾部增删元素较快,使用 push_back() 在尾部增加元素,使用 pop_back() 在尾部删除元素。
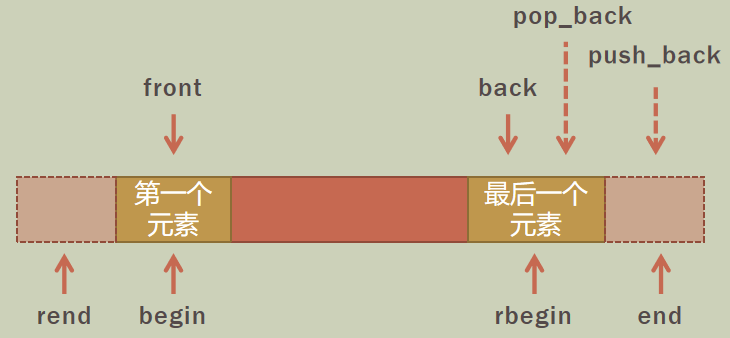
可以使用 insert() 在任意位置插入一个或一段元素,但效率较低,插入的位置由迭代器来表示;erase() 则可以删除一个或一段元素,用法与 insert() 类似,效率也低。
1 | int main() { |
可以使用 resize() 来修改数组的长度,若修改后的长度比现有的要小,则舍弃后面的元素,否则添加缺省元素。
1 | int main() { |
1.2. deque
deque 实现了一个双端队列,通过动态数组来实现,可以快速地在数组的头尾两端增删元素,支持随机存储迭代器,可以在常数时间内完成随机存取元素。
所有适用于 vector 的操作都适用于 deque,除此之外,deque 还提供了这些成员函数:
front()取第一个元素(队首)的值back()取最后一个元素(队尾)的值push_front()将元素插入到最前面pop_front()删除第一个元素
1.3. list
list 实现了一个双向链表,不支持随机存取,支持双向迭代器,与 vector 相比,不支持用 [] 来访问任意位置的元素,也不支持将迭代器移动多个单位(即不支持 begin() + i 这样的操作),但支持向前或向后移动(即支持 ++ 和 — ),可以在末尾或开头快速增加或删除元素,在任何位置增删元素都能在常数时间完成。
1 | int main() { |
list 的构造函数与 vector 类似,可以指定一个初始长度,还可以分别指定初始长度和元素的初始值,也可以根据一个已有的数组来构造 list 对象。与 vector 类似,可以使用 insert() /erase() 在任意位置插入/删除一个或一段元素,且效率较高;与 vector 类似,可以使用 resize() 修改长度。
可以使用成员函数 reverse() 将整个链表反序。
1 |
|
可以使用成员函数 remove() 删除指定值的元素。
1 |
|
可以使用成员函数unique() 删除所有和前一个元素相同的元素,注意删除时只与前一个元素比较是否相同,所以最后得到的链表里仍然可能有重复的元素。还可以通过函数自定义元素相同的含义,将函数值返回 true 时,就删除当前元素
1 |
|
1 | bool is_near(double d1, double d2) { |
由于 list 不支持随机存取,因此无法使用STL中的 sort 算法模板进行排序,只能使用 list 自己的成员函数sort() 来排序,缺省按照 operator < 的含义来排序,可以重载 < 操作符。也可以传入函数指针,通过自定义的函数来重新定义元素的大小。
1 | bool cmp(int a, int b) { return a % 10 < b % 10; } |
可以使用成员函数 merge() 合并两个链表,并清空被合并的那个链表。合并的两个链表中的元素必须按照某种规则排好序,否则会出错,因此 merge() 经常配合 sort() 一起使用,合并后的链表也是排好序的,可以自定义排序规则。
1 | int main() { |
可以使用成员函数 splice() 在指定位置前面插入另一链表中的一个或多个元素,并在另一链表中删除这些被插入的元素。
1 | int main() { |
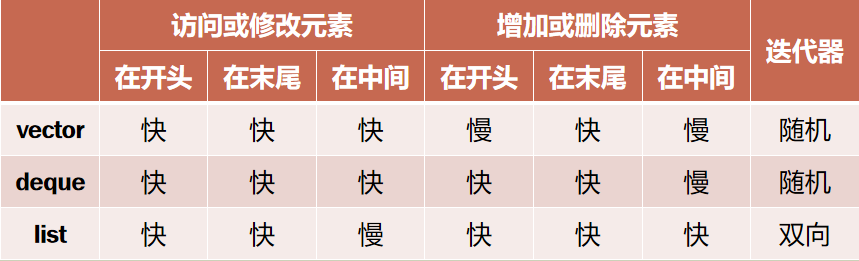
总结:常用的这三种顺序容器的主要差别在于访问/修改元素与增加/删除元素的速度上,因此需要根据实际情况选用合适的容器。
2.关联容器
在关联容器中,元素的插入位置与元素的值有关,必须按相应的排序准则来确定,在查找元素时具有非常好的性能:
set/multiset(声明于#include<set>)集合:实现了一棵平衡二叉搜索树,使用元素本身作为键值(key);
set容器中不允许存在相同元素,multiset容器中允许存在相同的元素map/multimap(声明于#include<map>)
映射表:实现了一棵平衡二叉搜索树,存放的是成对的键值和数据(key / value),并根据键值对元素进行排序,可快速地根据键值来检索元素;map容器中不允许存在键值相同的元素,而multimap容器中则允许C++11 中新增的
unordered_set/unordered_multiset(声明于 < unordered_set>)和unordered_map/unordered_multimap(声明于 < unordered_map>)
映射表:通过哈希表实现,功能与set/multiset和map/multimap相似,但不对键值排序
键值与数据(key-value pair):在关联容器中,通过键值来查询对应的数据,对于集合容器来说,键值与数据相等。
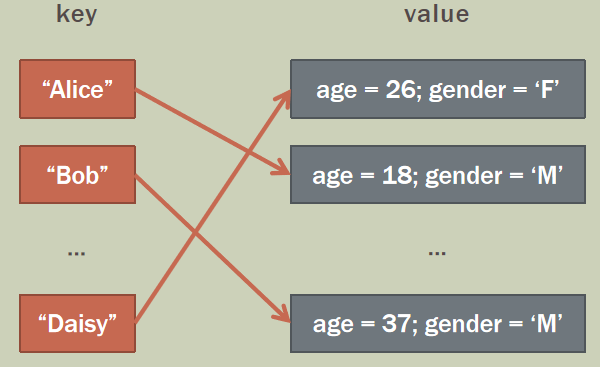
pair:可以使用 pair 模板来生成 key-value 对,pair 声明于 < utility> 头文件中,pair 中有两个成员变量 first 和 second:first 表示 key,second 表示 value。实例化的 pair 模板类可以用来绑定两个对象为一个新的对象。
比较两个 pair 对象的大小:
p1 < p2:如果p1.first < p2.first或者!(p2.first < p1.first) && p1.second < p2.second,则返回truep1 == p2:如果p1.first == p2.first && p1.second == p2.second,则返回true
声明一个 pair 对象:
pair<T1, T2> p:创建一个空的 pair 对象,它的两个元素分别是 T1 和 T2 类型,采用值初始化pair<T1, T2> p(v1, v2):创建一个 pair 对象,它的两个元素分别是 T1 和 T2 类型,其中 first 成员初始化为 v1,second 成员初始化为 v2make_pair(v1, v2):以 v1 和 v2 值创建一个新的 pair 对象,其元素类型分别是 v1 和 v2 的类型
2.1. set/multiset
set / multiset 是集合容器,实现了一棵平衡二叉搜索树,使用元素本身作为键值(key)。set 容器中不允许存在相同元素,而 multiset 容器中允许内部元素有序排列,新元素插入的位置取决于其值。
支持双向迭代器,不支持 [] 下标访问元素,但可以通过 find() 等成员函数快速查找元素,增加、删除、修改、查询元素的算法时间复杂度均为$O( \log n)$。可根据 operator < 来比较两个元素的大小,对于自定义的类,需要重载其 < 操作符。
2.1.1. set
可使用成员函数 insert() 向集合中增加元素,根据元素对应的 operator < 来确定元素应处的位置,插入容器中已有的元素时,插入操作失败(即不会插入重复的元素)。
1 | int main() { |
对于自定义的类,需要重载 operator <
1 | class Customer { |
几种查找元素的接口:
使用成员函数 find() 来查找容器中的某个元素 x,若能找到,则返回指向 x 的迭代器,否则返回 end(),在这里,两个元素的相等是根据 operator < 判断的(即同时满足 x < y 为假且 x > y 为假),与 operator == 运算符无关。
使用成员函数 lower_bound() 来查找容器中的某个元素 x,返回第一个大于等于 x 的元素的迭代器,若找不到则返回 end()。
使用成员函数 upper_bound() 来查找容器中的某个元素 x,返回第一个大于 x 的元素的迭代器,若找不到则返回 end()。
使用成员函数 equal_range() 来查找容器中的某个元素 x,返回一个迭代器对(pair),其 first 值就是 lower_bound() ,其 second 值就是 upper_bound()。
使用成员函数 count() 来计算等于某个值的元素个数。
注意通过迭代器访问元素时,先判断迭代器是否等于 end()。
1 |
|
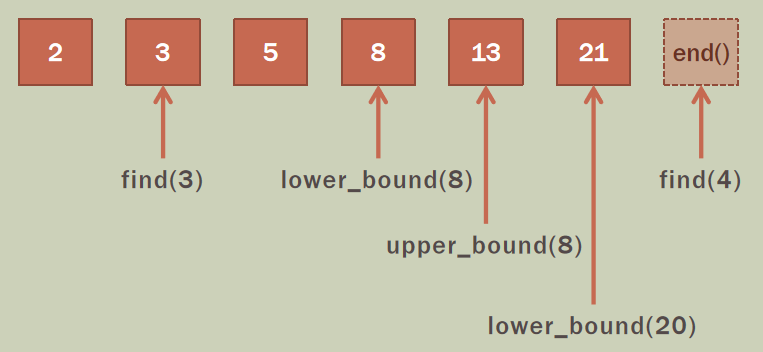
使用成员函数 erase() 来删除某个元素,传入的参数可以是元素值,若该元素不存在容器中,则删除失败;也可以是指向容器中某个元素的迭代器,迭代器必须是有效的;还可以传入两个迭代器,表示一段左闭右开的区间。
erase()与 find() 、lower_bound()、upper_bound() 以及 begin()、end()、rbegin()、rend() 等配合使用,可以达到一些常见的效果,使用时注意 STL 中的区间一般都是左闭右开的,例如 [ begin(), end() )以及 lower_bound() 与 upper_bound() 在相等元素上的处理区别。
如下程序,假设普通函数 disp(set< int>) 用于输出容器中的所有元素
1 | int main() { |
2.1.2. multiset
multiset 在使用上与 set 基本一致,主要区别在于 multiset 允许插入值相同的元素。在使用 find() 查找时,会返回第一个等于该查找值的元素,在使用 erase() 删除等于某个值的元素时,会删除所有等于该值的元素
假设 multiset< int> s 中的元素如下:
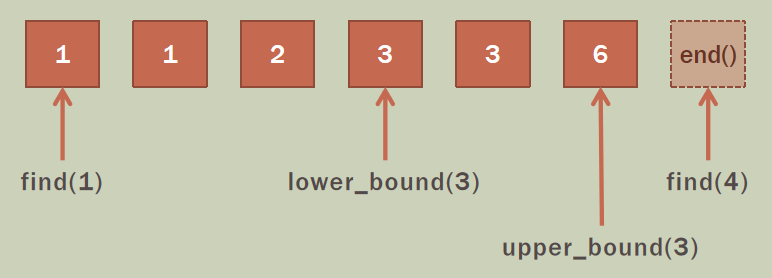
如下程序,假设普通函数 disp() 用于输出容器set< int>和multiset< int>中的所有元素。
1 | int main() { |
示例:s1 是一个不允许重复元素的集合,且元素按降序排列,因此输出 9 7 5 3 1;s2 是一个允许有重复元素的容器,缺省将元素按升序排列,因此输出 1 3 3 5 7 9。
1 | int main() { |
2.2. map/multimap
map / multimap 是一张映射表,通过平衡二叉搜索树来实现,存放的是成对的 key-value,实例化时需要在 <> 中依次指定 key 和 value 的类型,根据 key 对元素进行排序,可快速地根据 key 来检索元素。map 容器中不允许存在 key 相同的元素,而 multimap 容器中则允许,用法与 set / multiset 类似。
支持双向迭代器,可以通过 find() 等成员函数快速查找元素,增加、删除、修改、查询元素的算法时间复杂度均为 $O(\log n)$。根据 operator < 来比较两个元素的大小,对于自定义的类,需要重载其 < 操作符。
2.2.1. map
可以使用成员函数 insert() 向 map 容器中插入元素,注意插入的元素是成对的 key-value,因此是一个个的 pair。可以通过迭代器访问元素,也可以使用 [] 运算符访问容器中已有的 key 对应的元素。
1 | int main() { |
旧一些的编译器只支持通过 make_pair() 的方式插入元素,新一些的编译器则可以直接通过 [] 来插入元素,如 m[“Alice”] = 18; 。因此当使用 [] 访问元素时,如果 [] 中的 key 不存在于容器中,则可能运行出错,也可能访问到一个未正确初始化的元素(其值不一定有意义)。当向容器中插入一个 key 已经存在的元素时,插入失败,但是可以通过 [] 来修改 key 对应的 value。
使用成员函数 erase() 删除元素,可以传入 key 作为参数,也可以传入指定元素的迭代器;还可以传入两个迭代器,表示删除一个左闭右开的区间内的所有元素。
使用成员函数 find()、lower_bound()、upper_bound() 或者 begin() 、rbegin() 等时,返回的都是 pair 迭代器,因为返回值对应于容器中的元素,而 map 容器中的元素是一个个 pair。
成员函数 equal_range() 的返回值则是一个由两个 pair 组成的 pair 迭代器,例如对于 map<string, int> 容器来说,equal_range() 的返回值类型为 pair<map<string, int>::iterator, map<string, int>::iterator>。因为 equal_range() 返回的是 lower_bound() 和 upper_bound() 构成的 pair,而 map 的 lower_bound() 和 upper_bound() 都是 pair 迭代器。
2.2.2. multimap
multimap 在使用上与 map 基本一致,主要区别在于 multimap 允许插入 key 相同的元素。multimap 不支持使用 [] 运算符访问元素,因为元素的 key 可能重复,用 [] 访问时可能不知道应该访问哪一个。
1 | int main() { |
3.容器适配器
在容器适配器中,不提供真正的用于存储元素的数据结构实现,不支持迭代器,由使用者选择合适的底层数据结构:
stack(声明于#include<stack>)
栈:是项的有限序列,并满足序列中被删除、检索和修改的项只能是最近插入序列的项,即按照后进先出的原则queue (声明于
#include<queue>)
队列:插入只可以在尾部进行,删除、检索和修改只允许从头部进行,即按照先进先出的原则priority_queue(声明于#include<queue>)
优先队列:最高优先级元素总是第一个出队,可视作堆
容器适配器可以用某种顺序容器来实现,即让已有的顺序容器以栈/队列的方式工作。
3.1. stack
stack 栈是一种后进先出的数据结构,只能插入、删除、访问栈顶元素。对应的操作为:
push()入栈 / 插入元素pop()出栈 / 删除元素top()返回栈顶元素的引用 / 访问元素
此外还可以通过成员函数 empty() 来判断栈是否为空,如果想要清空一个栈,只能通过 while (!empty()) pop(); 这样的方式。如下图依次演示了:1 入栈、2 入栈、3 入栈、3 出栈、1 入栈、4 入栈。

stack 在缺省情况下用 deque 实现:template<class T, class Cont = deque<T> >,例如 stack<int> s; 声明了一个元素为 int 型的栈,用 deque 实现。但也可以用 vector 或 list 来实现,例如 stack<string, vector<string> > s; 声明了一个元素为 string 型的栈,用 vector 实现。在声明时可以同时对栈初始化,初始化方式与 vector / deque / list 类似。
3.2. queue
queue 队列是一种先进先出的数据结构,只能在队尾插入元素,只能访问或删除队首元素,对应的操作为:
push()入队 / 插入元素pop()出队 / 删除元素front()返回队首元素的引用 / 访问元素
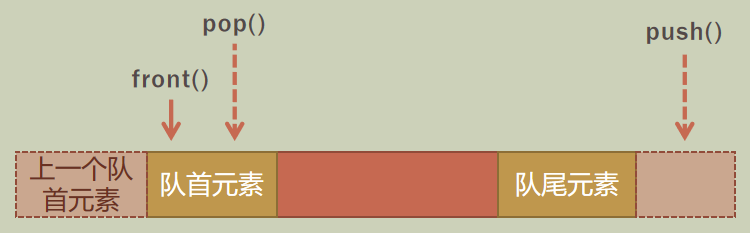
queue 在缺省情况下用 deque 实现:template<class T, class Cont = deque<T> >。例如 queue<int> q; 声明了一个元素为 int 型的队列,用 deque 实现。但也可以用 vector 或 list 来实现,例如 queue<string, vector<string> > q; 声明了一个元素为 string 型的队列,用 vector 实现。在声明时可以同时对队列初始化,初始化方式与 vector / deque / list 类似。
3.3. priority_queue
priority_queue 是一个优先队列,也可以看做是一个堆(heap),能保证最大的元素总是在最前面,一些操作为:
pop()删除的是队列中最大的元素(因为最大的元素总是在队首)没有名叫
front()成员函数,通过top()返回最大元素的引用通过
push()添加元素,每次push()之后队首元素可能发生变化
priority_queue用法基本和 queue 类似,可以用 vector 和 deque 实现,缺省情况下用vector 实现。缺省情况是根据 less<T> 模板比较大小的,实例化时是个函数对象。可以使用其他的函数对象类模板来定义大小,或者重载元素的 < 运算符,例如 priority_queue<int, vector<int>, greater<int> > 就声明了一个将最小的元素排在队首的优先队列。
例如下面声明了三种队列,设 disp() 可以按序输出队列中的元素。
1 | int main() { |
这一章中各容器在数据结构与算法中有详细的介绍,包括原理,实现,效率与优化等等,可以参考我的博客中数据结构与算法categories中的相关文章(┌・ω・)┌✧