1. Recipe of Deep Learning
回顾之前讲过的Deep Learning的三个步骤:
- define the function set(network structure)
- goodness of function(loss function — cross entropy)
- pick the best function(gradient descent — optimization)
做完这些步骤以后会得到一个更好的neural network,那接下来我们要做什么事情呢?
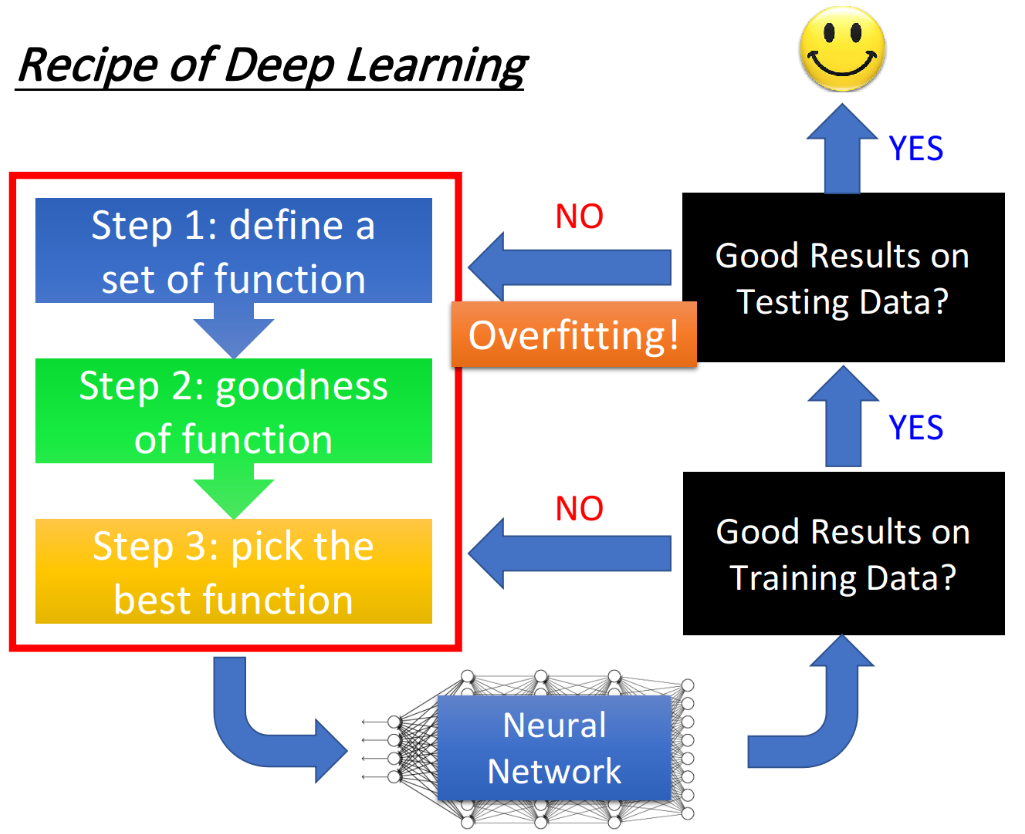
Good Results on Training Data?
要做的第一件事是,提高model在training set上的正确率。
先检查training set的performance其实是deep learning一个非常unique的地方,如果使用的是k-nearest neighbor或decision tree这类非deep learning的方法,做完以后其实不用去检查training set的结果,因为在training set上的performance正确率就是100。Deep Learning的model里这么多参数,但实际上Deep Learning不容易出现overfitting,overfitting是指在training set上performance很好,但在testing set上performance没有那么好。像k nearest neighbor,decision tree这类方法,它们在training set上正确率都是100,是非常容易overfitting的;而对deep learning来说,overfitting往往不会是你遇到的第一个问题。
因为deep learning并不是像k nearest neighbor这种方法一样,一训练就可以得到非常好的正确率,它有可能在training set上没有办法给一个很好的正确率,所以,这个时候要回头去检查在前面的step里面要做什么样的修改,使得模型在training set上可以得到较高的正确率。
Good Results on Testing Data?
接下来要做的事是,提高model在testing set上的正确率。
假设现在已经在training set上得到好的performance了,那接下来就把model apply到testing set上,我们最后真正关心的,是testing set上的performance。如果得到的结果不好,这时就是Overfitting了,也就是在training set上得到好的结果,却在testing set上得到不好的结果。
那你要回过头试着解决overfitting,但有时候你加了新的technique,想要overcome overfitting这个problem的时候,其实反而会让training set上的结果变坏;所以你在做完这一步的修改以后,要先回头去检查新的model在training set上的结果,如果这个结果变坏的话,你就要从头对network training的process做一些调整,那如果你同时在training set还有testing set上都得到好结果的话,你就成功了,最后就可以把你的系统真正用在application上面了。
Do not always blame overfitting
不要看到不好的performance就归责于overfitting。先看右边testing data的图,横坐标是model做gradient descent所update的次数,纵坐标则是error rate(越低说明model表现得越好),黄线表示的是20层的neural network,红色表示56层的neural network。发现56层network的error rate比较高,它的performance比较差,而20层network的performance则是比较好的,有些人看到这就会马上得到一个结论:56层的network参数太多了,56层果然没有必要,这个是overfitting。
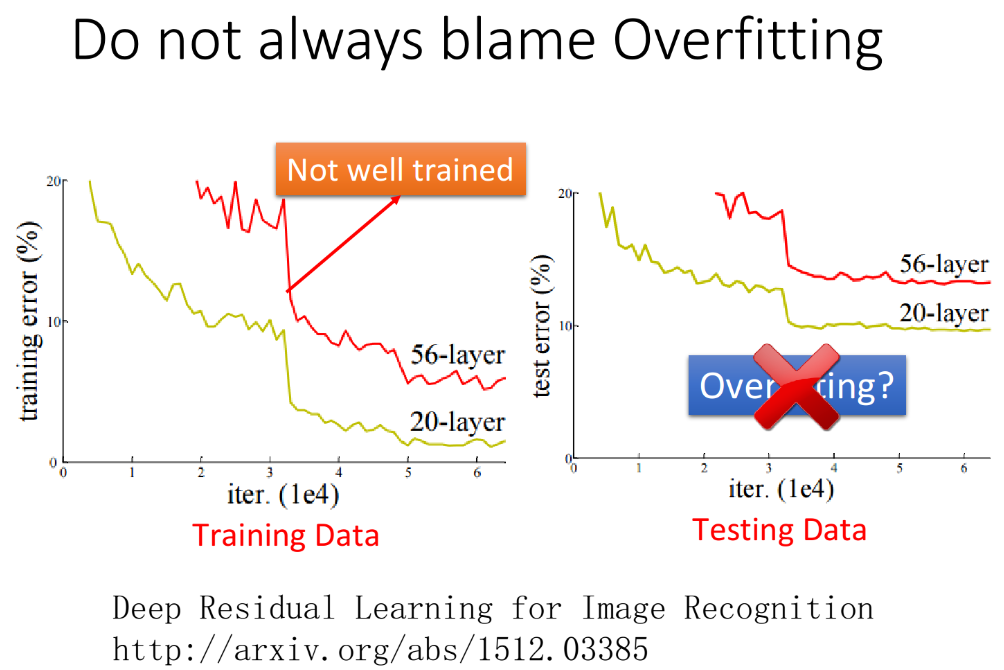
但是检查一下模型在training set上的performance,如上面左边的图,在training set上20层的network本来就要比56层的network表现得更好,所以testing set得到的结果并不能说明56层的case就是发生了overfitting。
在做neural network training的时候,有太多的问题会让training set表现的不好,比如local minimum的问题,saddle point的问题,有plateau的问题…所以这个56层的neural network有可能在train的时候就卡在了一个local minimum的地方,于是得到了一个差的参数,但这并不是overfitting,而是在training的时候就没有train好。有人认为这个问题叫做underfitting,但underfitting的本意应该是指这个model的complexity不足,这个model的参数不够多,所以它的能力不足以解出这个问题;但这个56层的network,它的参数是比20层的network要来得多的,所以它明明有能力比20层的network要做的更好,却没有得到理想的结果,这种情况不应该被称为underfitting,其实就只是没有train好而已。
当你在deep learning的文献上看到某种方法的时候,永远要想一下,这个方法是要解决什么样的问题:
- 在training set上的performance不够好
- 在testing set上的performance不够好
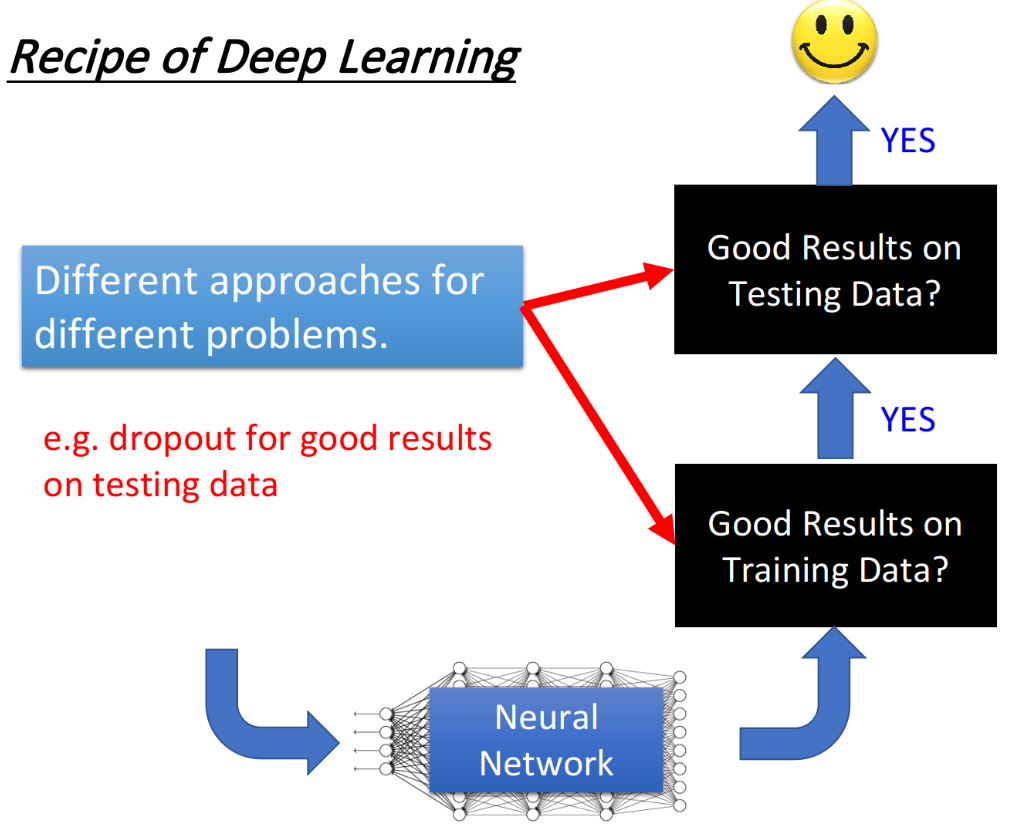
当只有一个方法propose(提出)的时候,它往往只针对这两个问题的其中一个来做处理,比如dropout的方法,它是在testing data的结果不好时用,如果你的问题只是training的结果不好,那去apply dropout只会越train越差。所以我们必须要先想清楚现在的问题到底是什么,然后再根据这个问题去找针对性的方法,而不是病急乱投医,甚至是盲目诊断。下面我们分别从Training data和Testing data两个问题出发,来讲述一些针对性优化的方法。
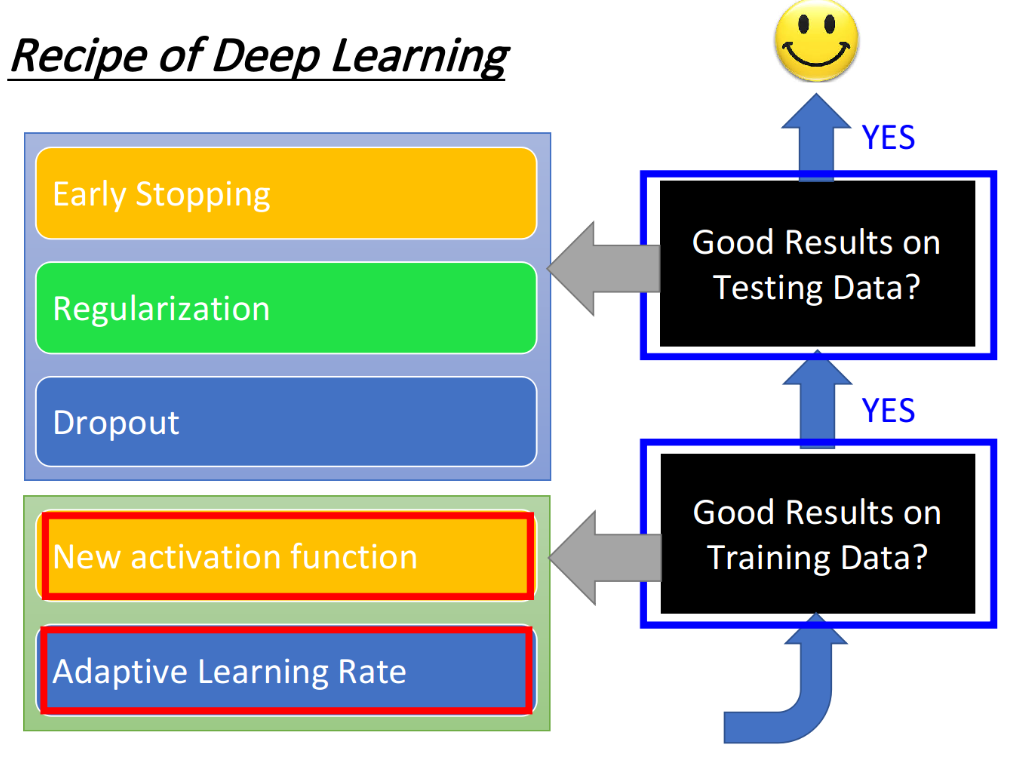
2. Good Results on Training Data?
这一章主要介绍如何在Training data上得到更好的performance,分为两个模块,New activation function和Adaptive Learning Rate。
2.1. New activation function
activation function
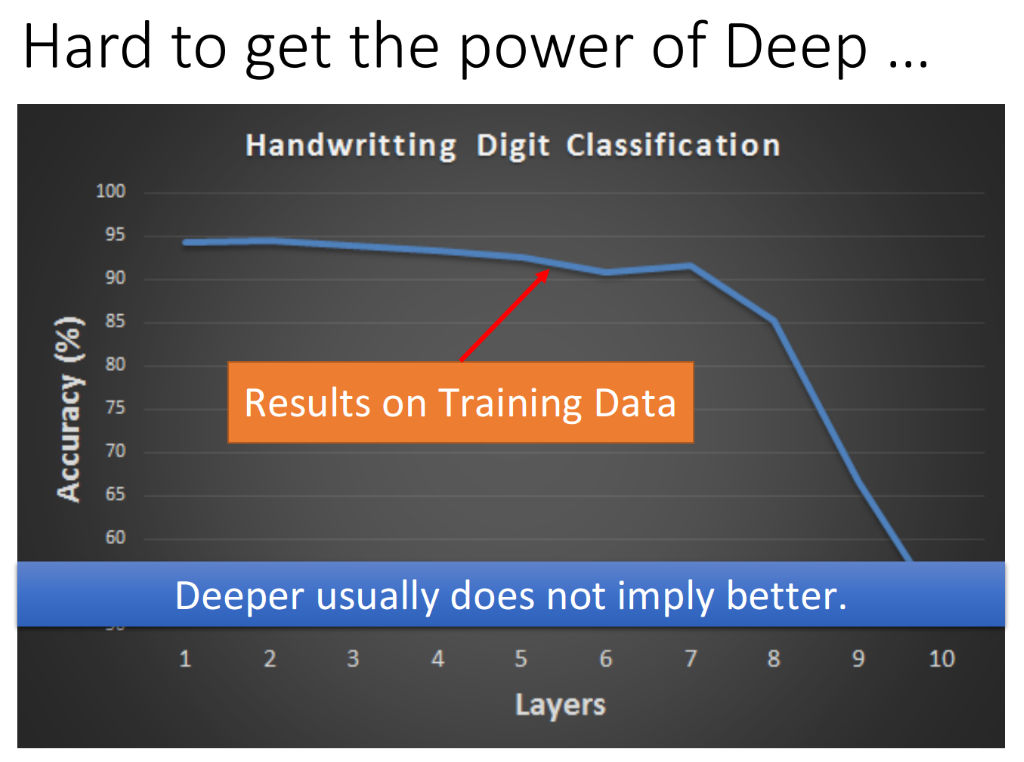
如果你今天的training结果不好,很有可能是因为你的network架构设计得不好。可能你用的activation function是对training比较不利的,那就要尝试着换一些新的activation function,也许可以带来比较好的结果。在1980年代,比较常用的activation function是sigmoid function,如果现在我们使用sigmoid function,你会发现network越deeper不一定imply better,下图是在MNIST手写数字识别上的结果,当layer越来越多的时候,accuracy一开始持平,后来就会逐渐降低,在layer是9层、10层的时候,整个结果就崩溃了。但注意9层、10层的情况并不能被认为是因为参数太多而导致overfitting,实际上这张图就只是training set的结果。
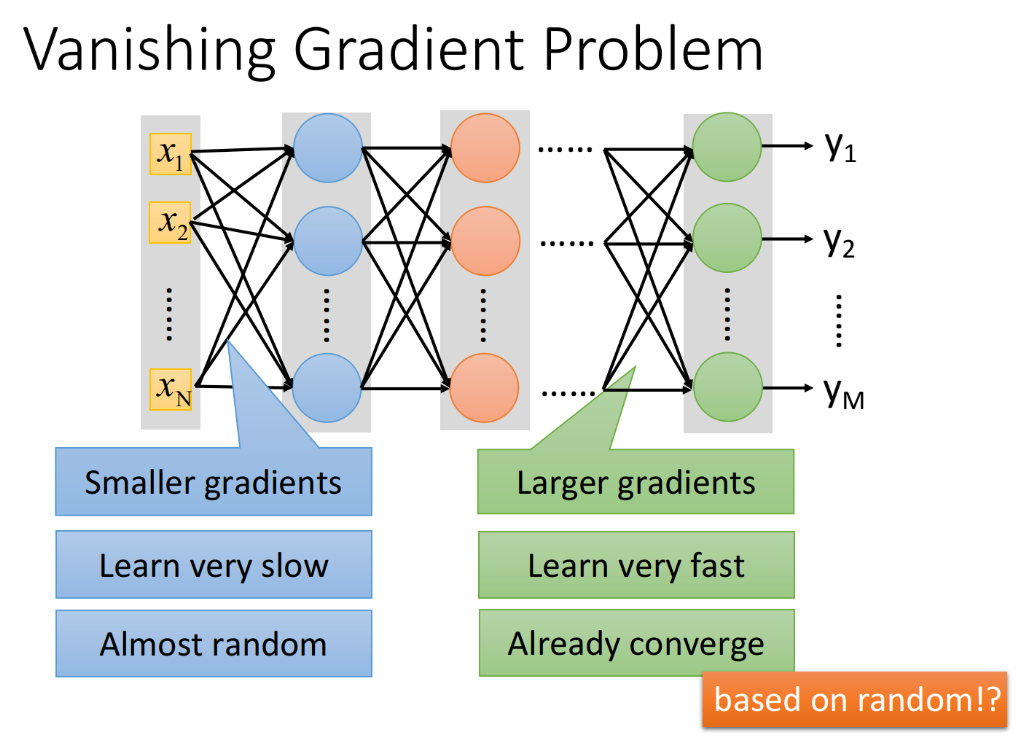
2.1.1. Vanishing Gradient Problem
上面这个问题的原因不是overfitting,而是Vanishing Gradient(梯度消失),解释如下:当你把network叠得很深的时候,在靠近input的地方,loss function对这些参数的微分(即梯度)是比较小的;而在比较靠近output的地方,它对loss的微分值会是比较大的。
因此当你设定同样learning rate的时候,靠近input的地方,它参数的update是很慢的;而靠近output的地方,它参数的update是比较快的。所以在靠近input的地方,参数几乎还是random的时候,output就已经根据这些random的结果找到了一个local minima,然后就converge(收敛)了。这时loss下降的速度变得很慢,你就会觉得gradient已经接近于0了,于是把程序停掉了,由于这个converge,是几乎base on random的参数,所以model的参数并没有被训练充分,那在training data上得到的结果肯定是很差的。
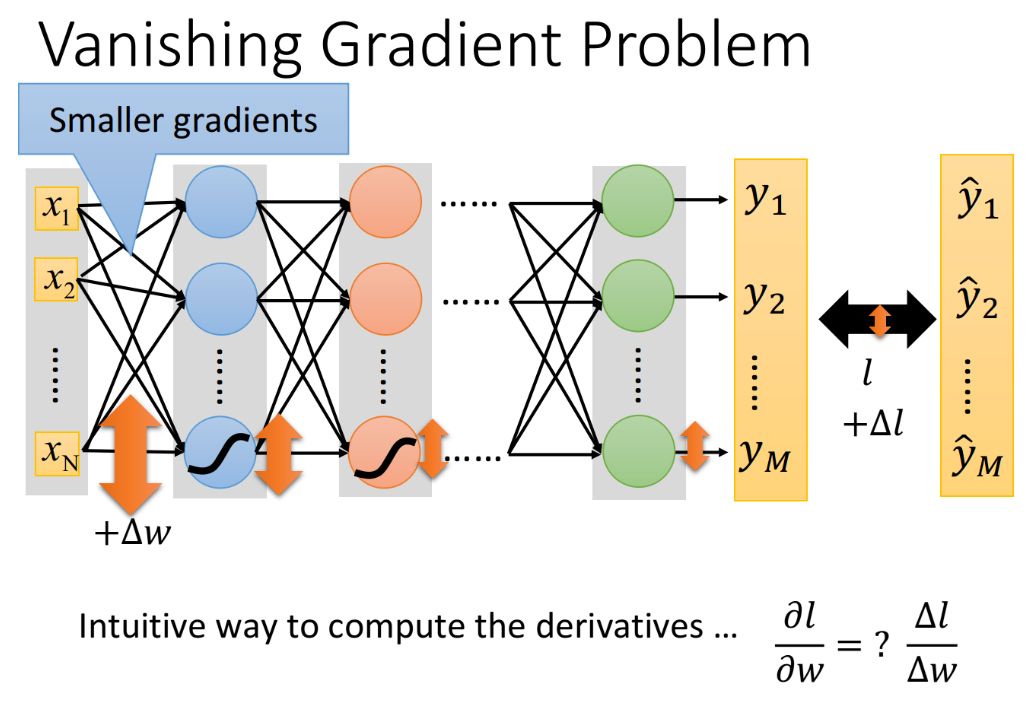
如果把Backpropagation的式子写出来,就可以很轻易地发现用sigmoid function会导致这件事情的发生;或者其实从直觉上来想也可以了解这件事情发生的原因:某一个参数$w$对total loss $l$的偏微分,即gradient $\frac{\partial l}{\partial w}$,它的含义可以理解为:当把这个参数做小小的变化的时候,它对loss的影响有多大;那我们就把第一个layer里的某一个参数$w$加上$\Delta w$,看看它对network的output和target之间的loss有什么样的影响。
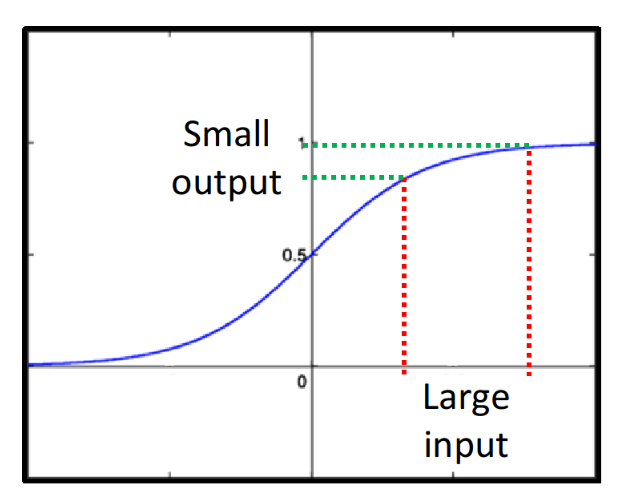
$\Delta w$通过sigmoid function之后,得到output是会变小的,改变某一个参数的weight,会对某个neuron的output值产生影响,但是这个影响是会随着层数的递增而衰减的,sigmoid function的形状如下所示,它会把负无穷大到正无穷大之间的值都硬压到0~1之间,把较大的input压缩成较小的output。
因此即使$\Delta w$值很大,但每经过一个sigmoid function就会被缩小一次,所以network越深,$\Delta w$被衰减的次数就越多,直到最后,它对output的影响就是比较小的,相应的也导致input对loss的影响会比较小,于是靠近input的那些weight对loss的gradient $\frac{\partial l}{\partial w}$远小于靠近output的gradient。
那如何解决这个问题呢?比较早年的做法是去train RBM(Restricted Boltzmann Machine,受限玻尔兹曼机),它的思想是:先把第一个layer train好,再去train第二个,然后再第三个…所以最后你在做Backpropagation的时候,尽管第一个layer几乎没有被train到,但一开始在做pre-train的时候就已经把它给train好了,这样RBM就可以在一定程度上解决问题。但其实改一下activation function可能就可以handle这个问题了。
2.1.2. ReLU
现在比较常用的activation function叫做Rectified Linear Unit(整流线性单元函数,又称修正线性单元),它的缩写是ReLU,该函数形状如下图所示,$z$为input,$a$为output,如果input>0则output = input,如果input<0则output = 0。

选择ReLU作为activation function的理由如下:
- 跟sigmoid function比起来,ReLU的运算快很多;
- ReLU的想法结合了生物上的观察( Pengel的paper );
- 无穷多bias不同的sigmoid function叠加的结果会变成ReLU;
- ReLU可以处理Vanishing gradient的问题( the most important thing );
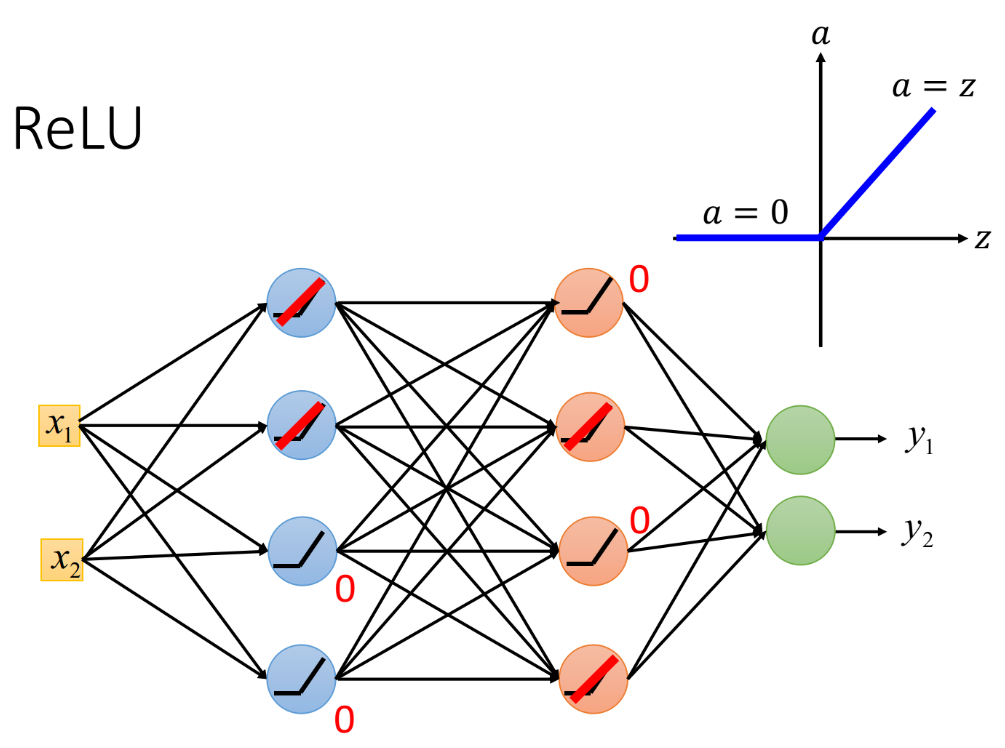
handle Vanishing gradient problem
下图是以ReLU作为activation function的neuron组成的network,它的output要么等于0,要么等于input。当output=input的时候,这个activation function就是linear的;而output=0的neuron对整个network是没有任何作用的,因此可以把它们从network中拿掉。
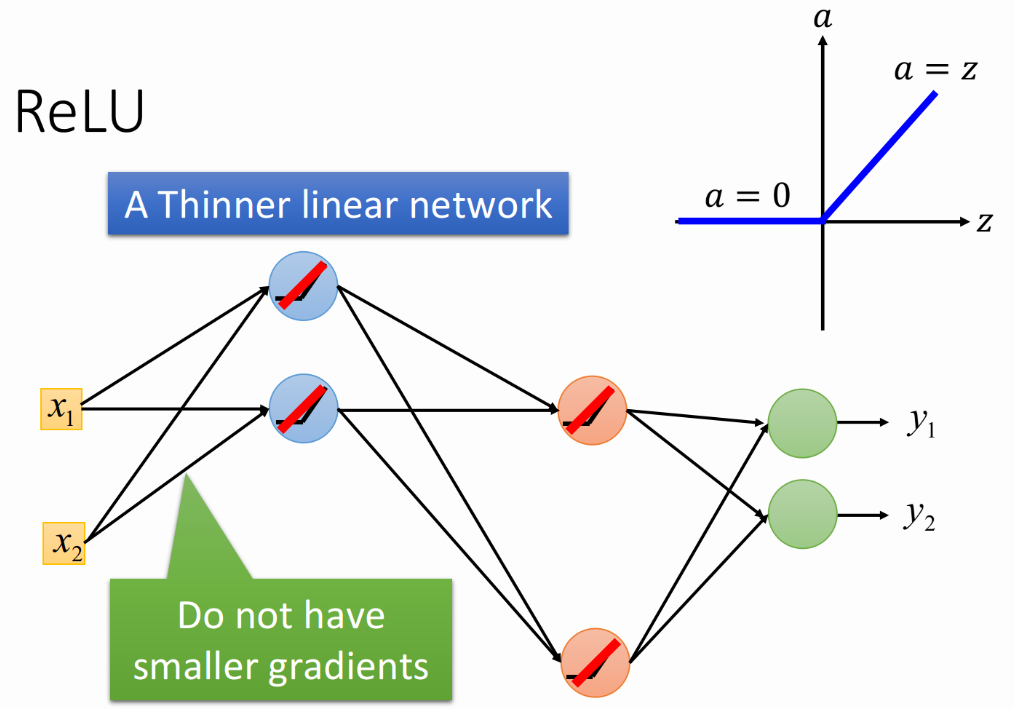
拿掉所有output为0的neuron后如下图所示,此时整个network就变成了一个瘦长的linear network,linear的好处是,output=input,不会像sigmoid function一样使input产生的影响逐层递减。
Q:这里就会有一个问题,我们之所以使用deep learning,就是想要一个non-linear、比较复杂的model,而使用ReLU不就会让它变成一个linear function吗?这样得到的function不是会变得很弱吗?
A:其实,使用ReLU之后的network整体来说还是non-linear的,如果你对input做小小的改变,不改变neuron的operation region的话,那network就是一个linear function;但是,如果你对input做比较大的改变,导致neuron的operation region被改变的话,比如从output=0转变到了output=input,network整体上就变成了non-linear function。(这里的region是指input z<0和input z>0的两个范围)
Q:还有另外一个问题,我们对loss function做gradient descent,要求neural network是可以做微分的,但ReLU是一个分段函数,它是不能微分的(至少在z=0这个点是不可微的),那该怎么办呢?
A:在实际操作上,当region的范围处于z>0时,微分值gradient就是1;当region的范围处于z<0时,微分值gradient就是0;当z为0时,就不要管它,相当于把它从network里面拿掉
ReLU-variant
其实ReLU还存在一定的问题,比如当input<0的时候,output=0,此时微分值gradient也为0,你就没有办法去update参数了,那我们可以让input<0的时候,微分后还能有一定的值,比如令$a=0.01z$,这个函数叫做Leaky ReLU。
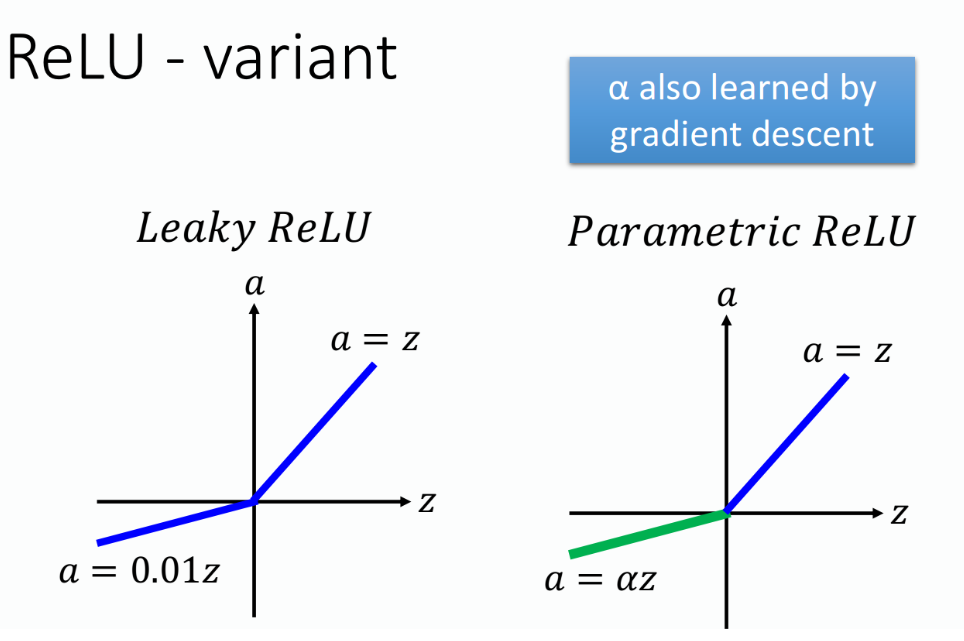
那自然可以想到我们也可以把$z$前的系数当作参数来训练,这就是Parametric ReLU,令$a=\alpha \cdot z$,其中$\alpha$并不是固定的值,而是network的一个参数,它可以通过training data学出来,甚至每个neuron都可以有不同的$\alpha$值。
又有人想,activation function为什么一定要是ReLU这样子呢,于是就有了一个更进阶的想法—Maxout network。
2.1.3. Maxout
Maxout的思想是,让network去学习它的activation function,那Maxout network就可以学出ReLU,也可以学出其他的activation function,这一切都是由training data来决定的。假设现在有input $x_1,x_2$,它们乘上几组不同的weight分别得到5,7,-1,1,这些值本来是不同neuron的input;但在Maxout network里,我们事先决定好将某几个“neuron”的input分为一个group,比如5,7分为一个group,然后在这个group里选取一个最大值7作为output。
这个过程就好像在一个layer上做Max Pooling一样,它和原来的network不同之处在于,它把原来几个“neuron”的input按一定规则组成了一个group,然后并没有使它们通过activation function,而是选取其中的最大值当做这几个“neuron”的output。
当然,实际上原来的”neuron“早就已经不存在了,这几个被合并的“neuron”应当被看做是一个新的neuron(下图中红框框住的部分),这个新的neuron的input是原来几个“neuron”的input组成的vector,output则取input的最大值,而并非由activation function产生。
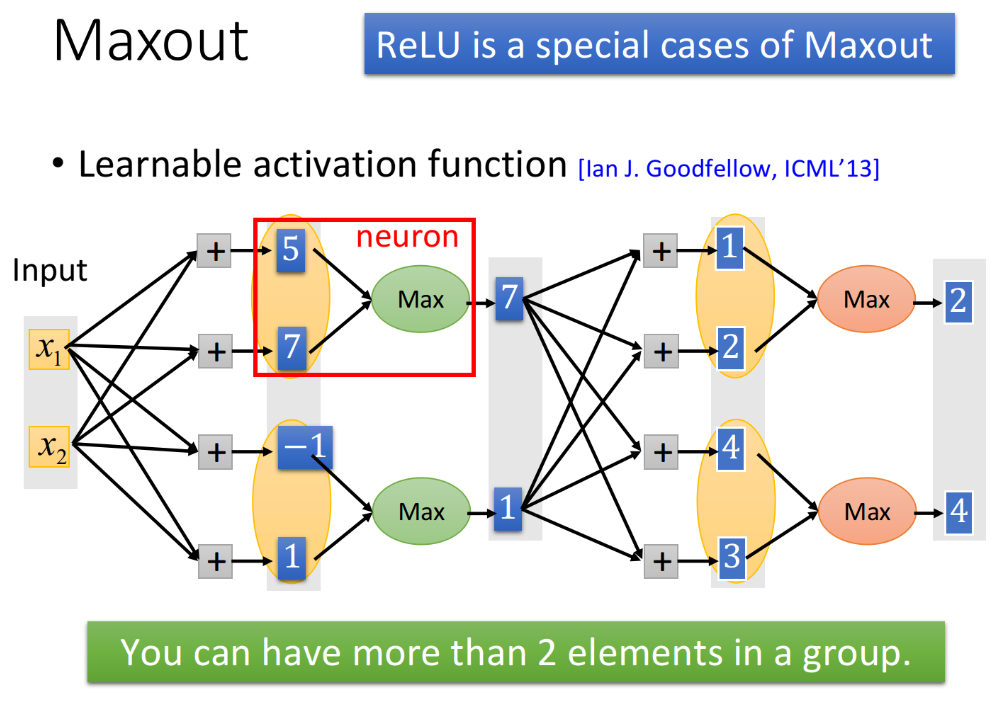
在实际操作上,几个element被分为一个group是由你自己决定的,它就是network structure里一个需要被调的参数,不一定要跟上图一样两个分为一组。
Maxout -> RELU
Maxout是如何能学习出ReLU这个activation function的呢?
下图左上角是一个ReLU的neuron,它的input $x$会乘上neuron的weight $w$,再加上bias $b$,然后通过activation function-ReLU,得到output $a$。
- neuron的input为$z=wx+b$,为下图左下角的紫线;
- neuron的output为$a=z\ (z>0);\ a=0\ (z<0)$,为下图左下角的绿线。
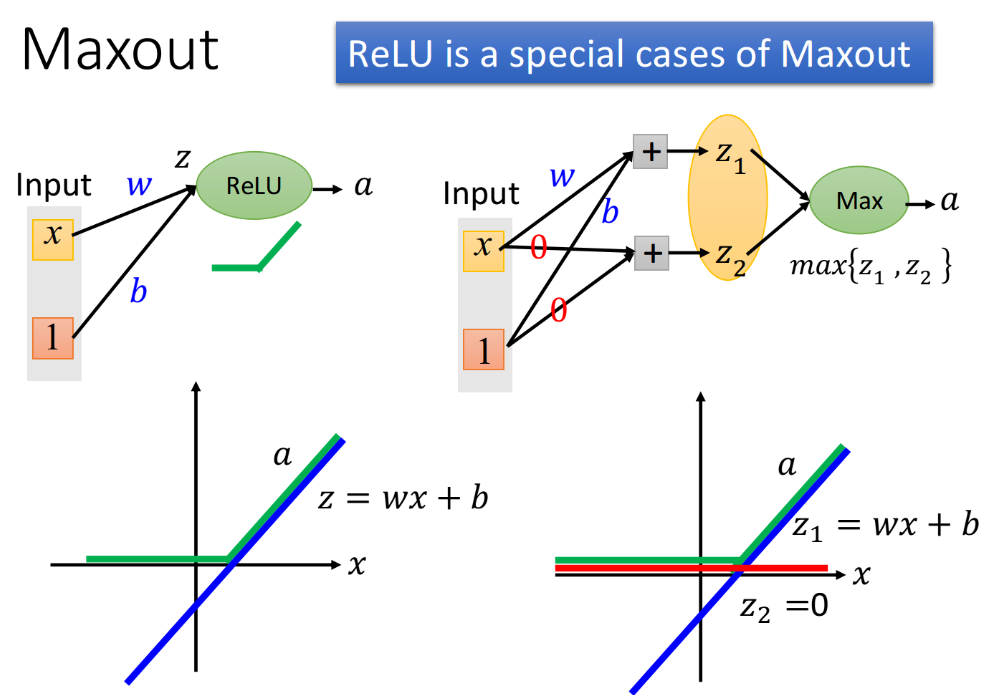
如果我们使用的是上图右上角所示的Maxout network,假设$z_1$的参数w和b与ReLU的参数一致,而$z_2$的参数w和b全部设为0,然后做Max,选取$z_1,z_2$较大值作为a:
- neuron的input为$\begin{bmatrix}z_1 \ z_2 \end{bmatrix}$
- $z_1=wx+b$,为上图右下角紫线
- $z_2=0$,为上图右下角红线
- neuron的output为$\max{\begin{bmatrix}z_1 \ z_2 \end{bmatrix}}$,为上图右下角绿线
你会发现,此时ReLU和Maxout所得到的output是一模一样的,它们是相同的activation function。
Maxout -> More than ReLU
除了ReLU,Maxout还可以实现更多不同的activation function。比如$z_2$的参数w和b不是0,而是$w’,b’$,此时
- neuron的input为$\begin{bmatrix}z_1 \ z_2 \end{bmatrix}$
- $z_1=wx+b$,为下图右下角紫线
- $z_2=w’x+b’$,为下图右下角红线
- neuron的output为$\max{\begin{bmatrix}z_1 \ z_2 \end{bmatrix}}$,为下图右下角绿线
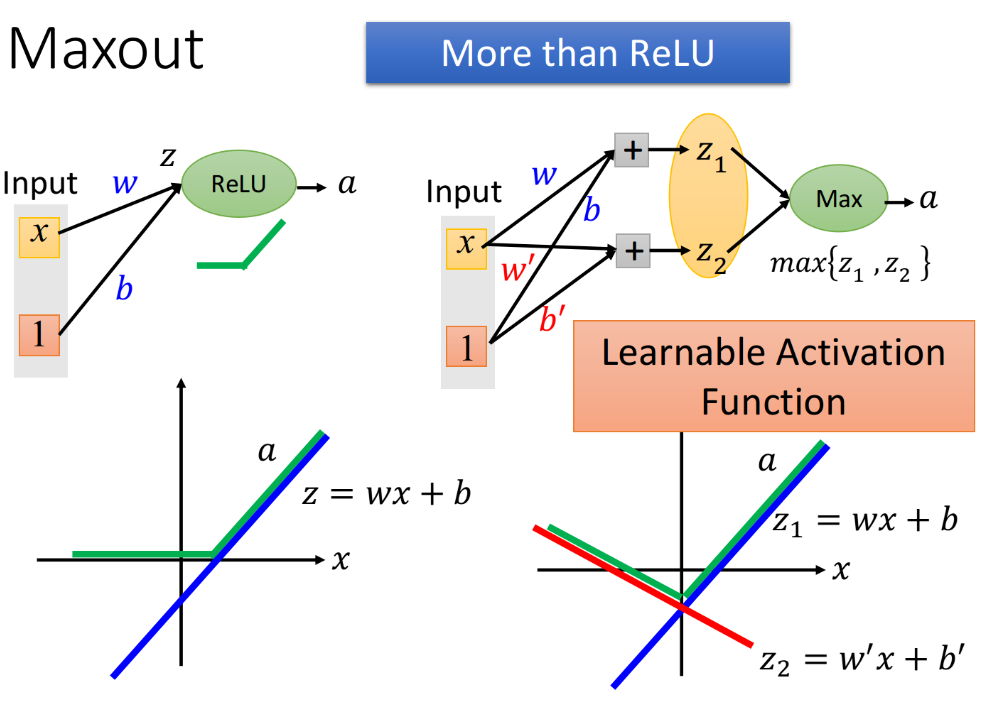
这个时候你得到的activation function的形状(绿线形状),是由network的参数$w,b,w’,b’$决定的,因此它是一个Learnable Activation Function,具体的形状可以根据training data去generate出来。
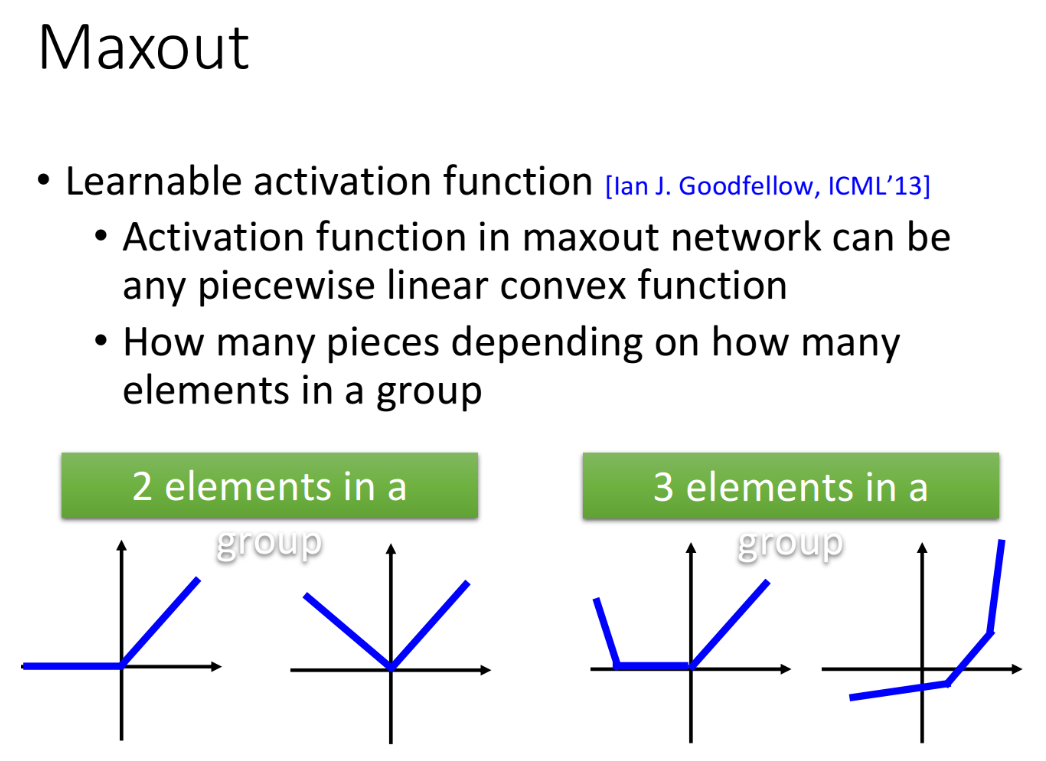
property
Maxout可以实现任何piecewise linear convex activation function(分段线性凸激活函数),其中这个activation function被分为多少段,取决于你把多少个element z放到一个group里,下图分别是2个element一组和3个element一组的activation function的不同形状。
How to train Maxout
接下来我们要面对的是,怎么去train一个Maxout network,如何解决Max不能微分的问题。假设在下面的Maxout network中,红框圈起来的部分为每个neuron的output。
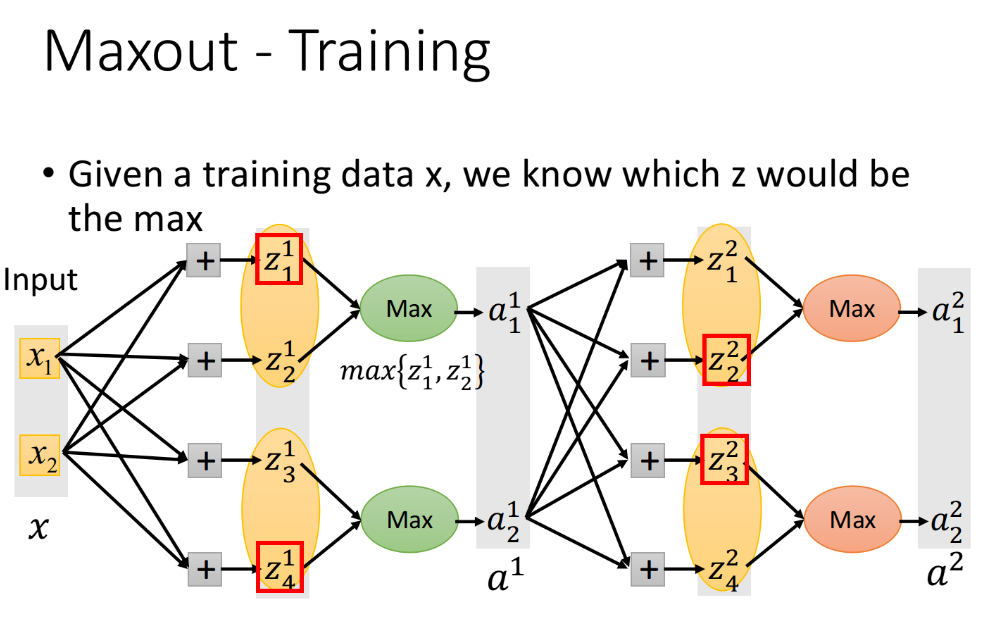
其实Max operation就是linear的operation,只是它仅接在前面这个group里的某一个element上,因此我们可以把那些并没有被Max连接到的element拿掉,从而得到一个比较细长的linear network。
那么可以理解为,实际上我们真正训练的并不是一个含有max函数的network,而是一个化简后如下图所示的linear network;当我们还没有真正开始训练模型的时候,此时这个network含有max函数无法微分,但是只要输入data,network就会根据这些data确定具体的形状,此时max函数的问题已经被实际数据给解决了,所以我们完全可以根据training data使用Backpropagation的方法去训练被network留下来的参数。
所以我们担心的max函数无法微分,它只是理论上的问题;在具体的实践上,完全可以先根据data把max函数转化为某个具体的函数,再对这个转化后的thiner linear network进行微分
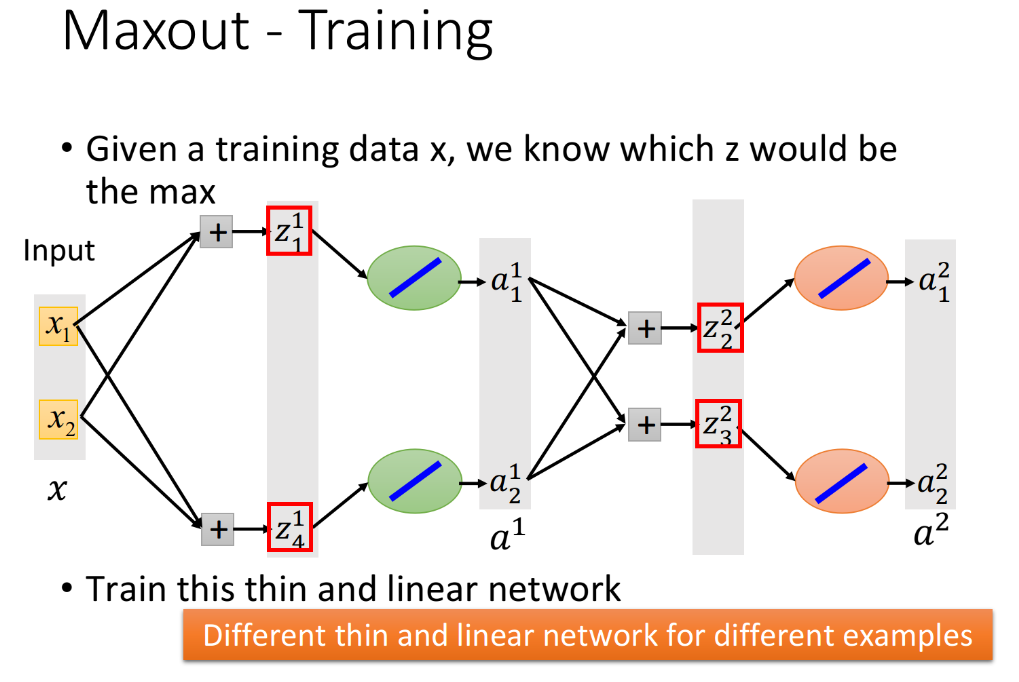
这个时候你也许会有一个问题,如果按照上面的做法,那岂不是只会train留在network里面的那些参数,剩下的参数该怎么办?那些被拿掉的直线(weight)岂不是永远也train不到了吗?
其实这也只是个理论上的问题,在实际操作上,每个linear network的structure都是由input的那一笔data来决定的,当input不同data的时候,得到的network structure是不同的,留在network里面的参数也是不同的,由于我们有很多笔training data,所以network的structure在训练中不断地变换,实际上最后每一个weight参数都会被train到。
所以,我们回到Max Pooling的问题上来,由于Max Pooling跟Maxout是一模一样的operation,那么Max Pooling有关max函数的微分问题就可以采用跟Maxout一样的方案来解决,至此我们已经解决了CNN部分的第一个问题—New activation function。
2.2. Adaptive learning rate
2.2.1. Review - Adagrad
回顾之前学过的梯度下降中的一个Tip: Adagrad,它让每一个parameter都要有不同的learning rate。Adagrad的思想是,假设我们考虑两个参数$w_1,w_2$,如果在$w_1$这个方向上,gradient都比较小,那它是比较平坦的,于是就给它比较大的learning rate;而在$w_2$这个方向上,gradient都比较大,那它是比较陡峭的,于是给它比较小的learning rate。
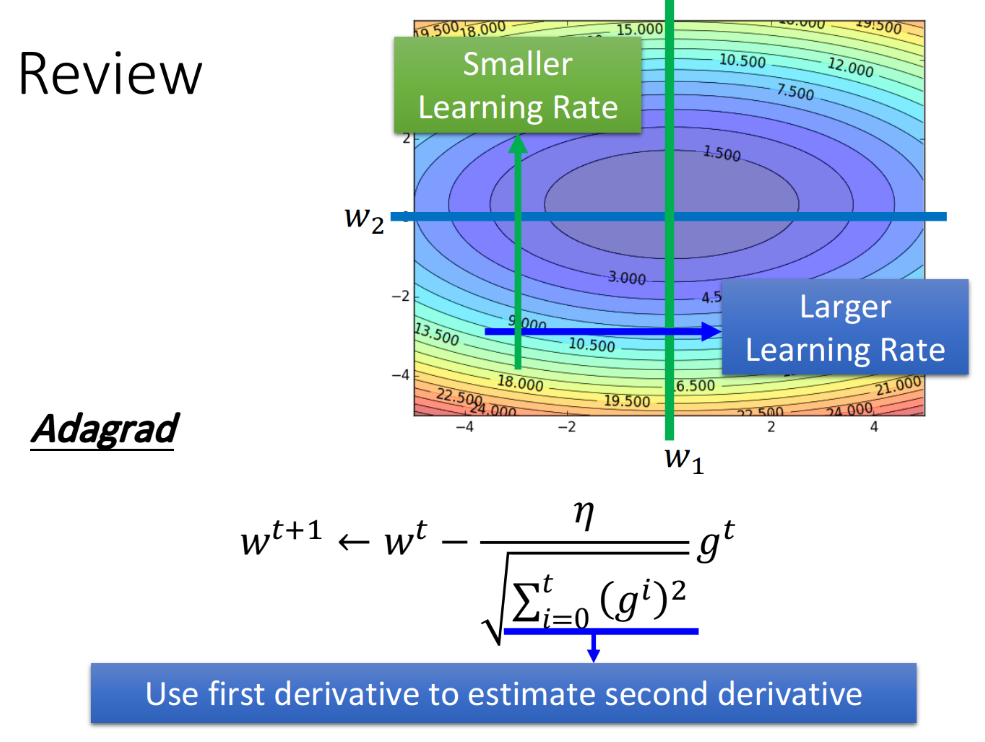
但我们实际面对的问题,很有可能远比Adagrad所能解决的问题要来的复杂,回顾之前学的Linear Regression,我们做optimization的对象,也就是loss function,它是convex的;但实际上我们在做deep learning的时候,这个loss function可以是任何形状。
2.2.2. RMSProp
learning rate
Deep learning的loss function可以是任何形状,对convex loss function来说,在每个方向上它会一直保持平坦或陡峭的状态,所以你只需要针对平坦的情况设置较大的learning rate,对陡峭的情况设置较小的learning rate即可。但在下图的情况中,即使是在同一个方向上(如w1方向),loss function也有可能一会儿平坦一会儿陡峭,所以就需要我们随时根据gradient的大小来快速地调整learning rate。
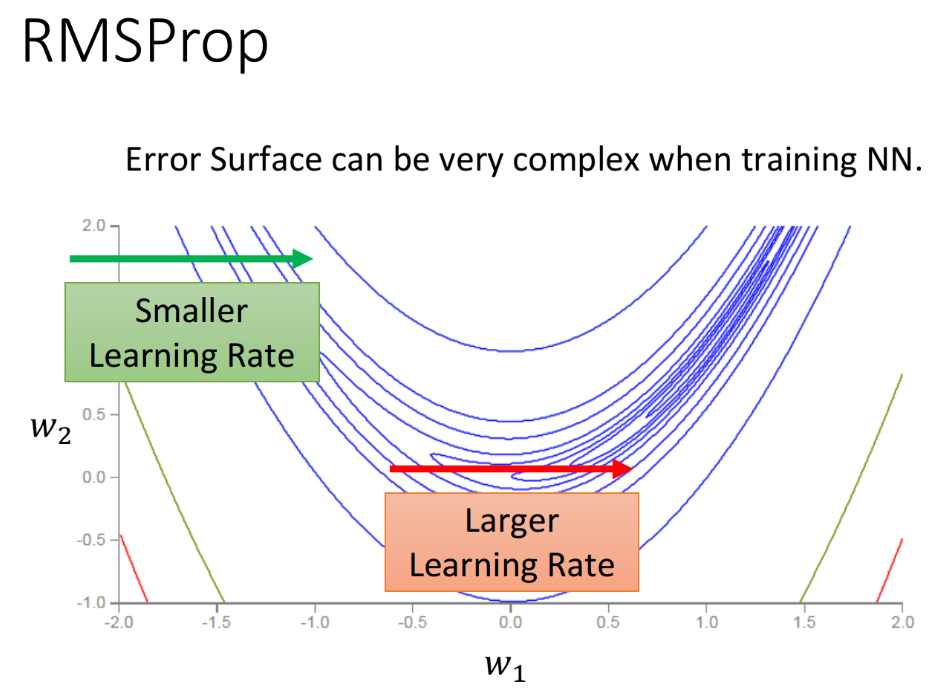
这个问题可以通过Adagrad的进阶版——RMSProp来解决。(RMSprop并不是在paper里提出来的,而是Hinton在他的网课里提出来的一个方法)
how to do RMSProp
RMSProp的做法如下:
learning rate依旧设置为一个固定的值 $\eta$ 除掉一个变化的值 $\sigma$,这个$\sigma$等于上一个$\sigma$和当前梯度$g$的加权方均根(特别的是,在第一个时间点,$\sigma^0$就是第一个算出来的gradient值$g^0$),即:
这里的$\alpha$值是可以自由调整的,RMSProp跟Adagrad不同之处在于,Adagrad的分母是对过程中所有的gradient取平方和开根号,也就是说Adagrad考虑的是整个过程平均的gradient信息;而RMSProp虽然也是对所有的gradient进行平方和开根号,但是它用$\alpha$来调整对不同gradient的权重,比如你把α的值设的小一点,意思就是你更倾向于相信新的gradient所告诉你的error surface的平滑或陡峭程度,而比较无视于旧的gradient所提供给你的information。

所以当做RMSProp的时候,你可以给现在已经看到的gradient比较大的weight,给过去看到的gradient比较小的weight,来调整对gradient信息的使用程度。
2.2.3. Momentum
optimization - local minima?
除了learning rate的问题以外,在做deep learning的时候,也会出现卡在local minimum、saddle point或是plateau的地方,很多人都会担心,deep learning这么复杂的model,可能会非常容易在这些地方“卡住”。但其实Yann LeCun在07年的时候,就提出了这样的观点:我们不需要太担心local minima的问题,因为一旦出现local minima,它就必须在每一个dimension都是下图中这种山谷的低谷形状,假设山谷的低谷出现的概率为p,由于我们的network有非常多的参数,比如有1000个参数,每一个参数都要位于山谷的低谷之处,这件事发生的概率为$p^{1000}$,当你的network越复杂,参数越多,这件事发生的概率就越低。
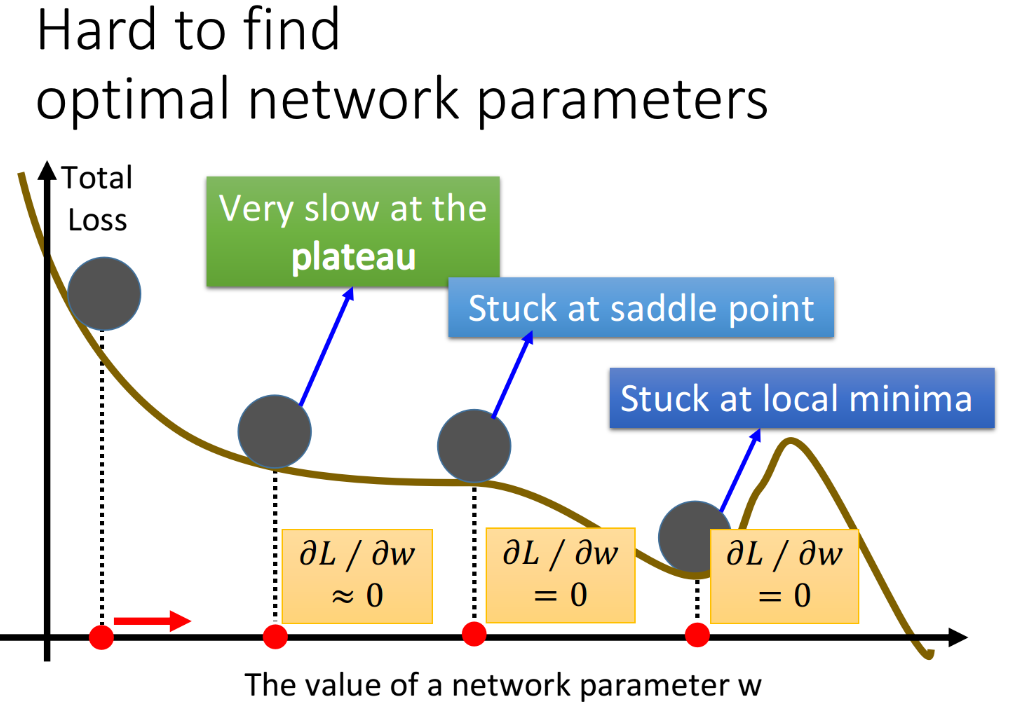
所以在一个很复杂的neural network里,其实并没有那么多的local minima,所以当算法运行到一个你觉得是local minima的地方被卡住了,那它八成就是global minima,或者是很接近global minima的地方。
where is Momentum from
有一个heuristic(启发性)的方法可以稍微处理一下上面所说的“卡住”的问题,它的灵感来自于物理中的惯性的概念。如果是在现实世界中,在有一个球从左上角滚下来,它会滚到plateau的地方、local minima的地方,但是由于惯性它还会继续往前走一段路程,假设前面的坡没有很陡,这个球就很有可能翻过山坡,走到比local minima还要好的地方。
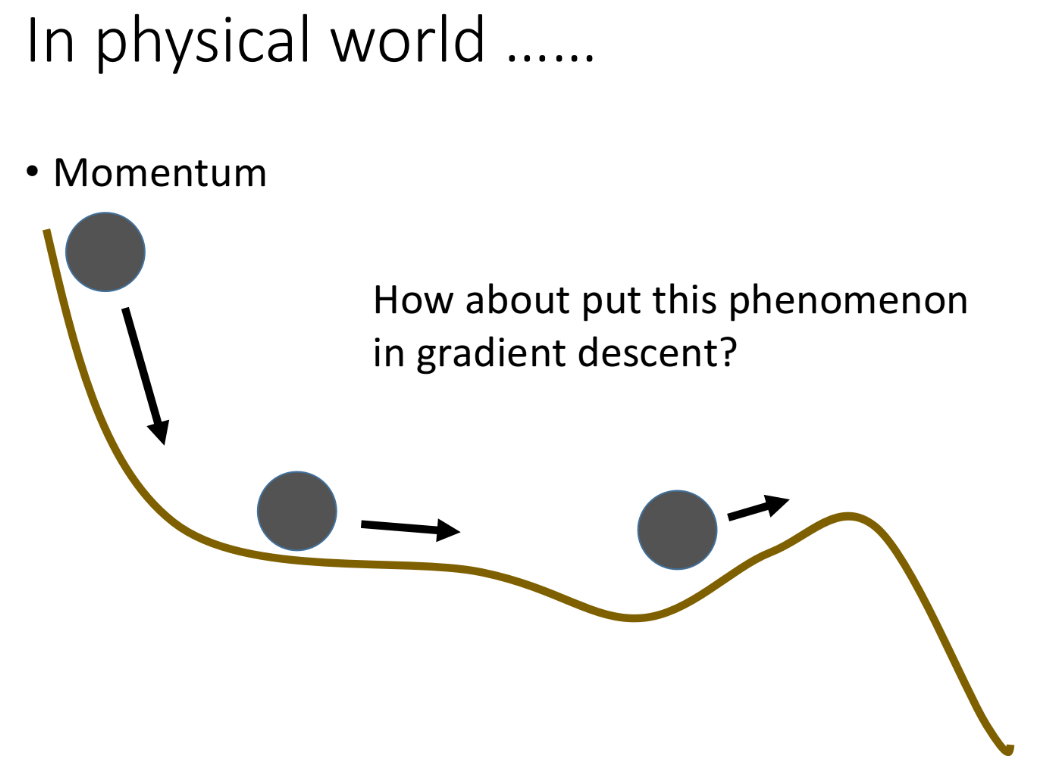
所以我们可以按照这个思路,把“惯性项”加到gradient descent里面,这就叫做Momentum。
how to do Momentum
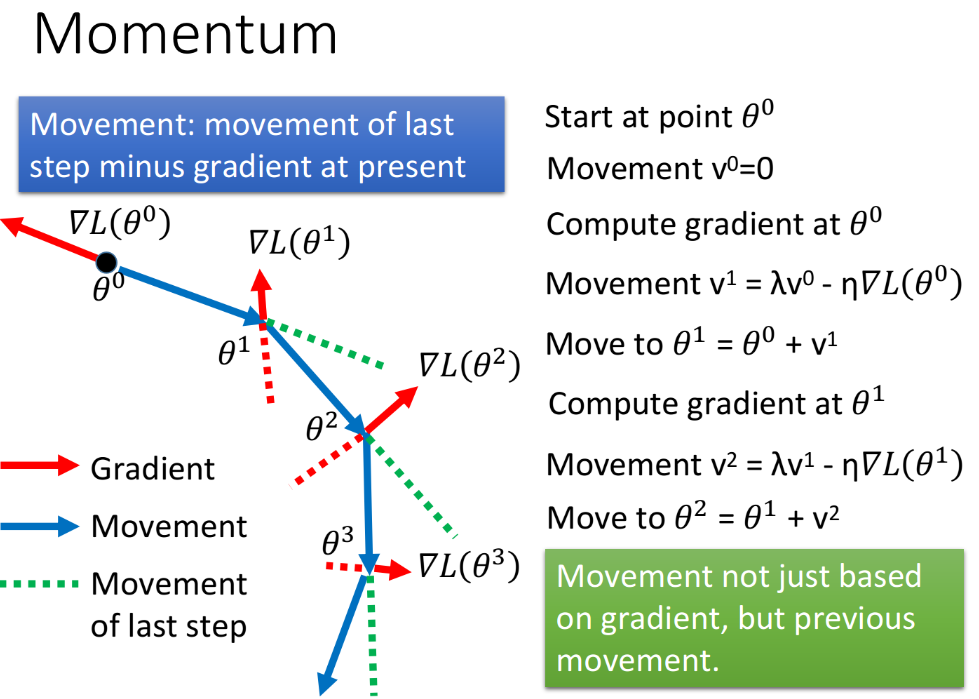
当我们在gradient descent里加上Momentum的时候,每一次update的方向,不再只考虑gradient的方向,还要考虑上一次update的方向,这里用变量$v$去记录前一个时间点update的方向。
随机选一个初始值$\theta^0$,初始化$v^0=0$,接下来计算$\theta^0$处的gradient,我们要移动的方向是由前一个时间点的移动方向$v^0$和gradient的反方向$\nabla L(\theta^0)$来决定的,即
注:这里的$\lambda$也是一个可以调整的参数,它表示惯性对前进方向的影响有多大。
接下来我们第二个时间点要走的方向$v^2$,它是由第一个时间点移动的方向$v^1$和gradient的反方向$\nabla L(\theta^1)$共同决定的;$\lambda v$是图中的绿色虚线,它代表由于上一次的惯性想要继续走的方向;$\eta \nabla L(\theta)$是图中的红色虚线,它代表这次gradient告诉你所要移动的方向;它们的矢量和就是这一次真实移动的方向,为蓝色实线
我们还可以用另一种方法来理解Momentum,其实你在每一个时间点移动的步伐$v^i$,包括大小和方向,就是过去所有gradient的加权和。
具体推导如下图所示,第一个时间点移动的步伐$v^1$是$\theta^0$处的gradient加权,第二个时间点移动的步伐$v^2$是$\theta^0$和$\theta^1$处的gradient加权和…以此类推;由于$\lambda$的值小于1,因此该加权意味着越是之前的gradient,它的权重就越小,即你更在意的是现在的gradient,但是过去的所有gradient也要对你现在update的方向有一定程度的影响,这就是Momentum。

当然也可以从直觉上来想一下加入Momentum之后是怎么运作的。下图中,红色实线是gradient建议我们走的方向,直观上看就是根据坡度要走的方向;绿色虚线是Momentum建议我们走的方向,实际上就是上一次移动的方向;蓝色实线则是最终真正走的方向。
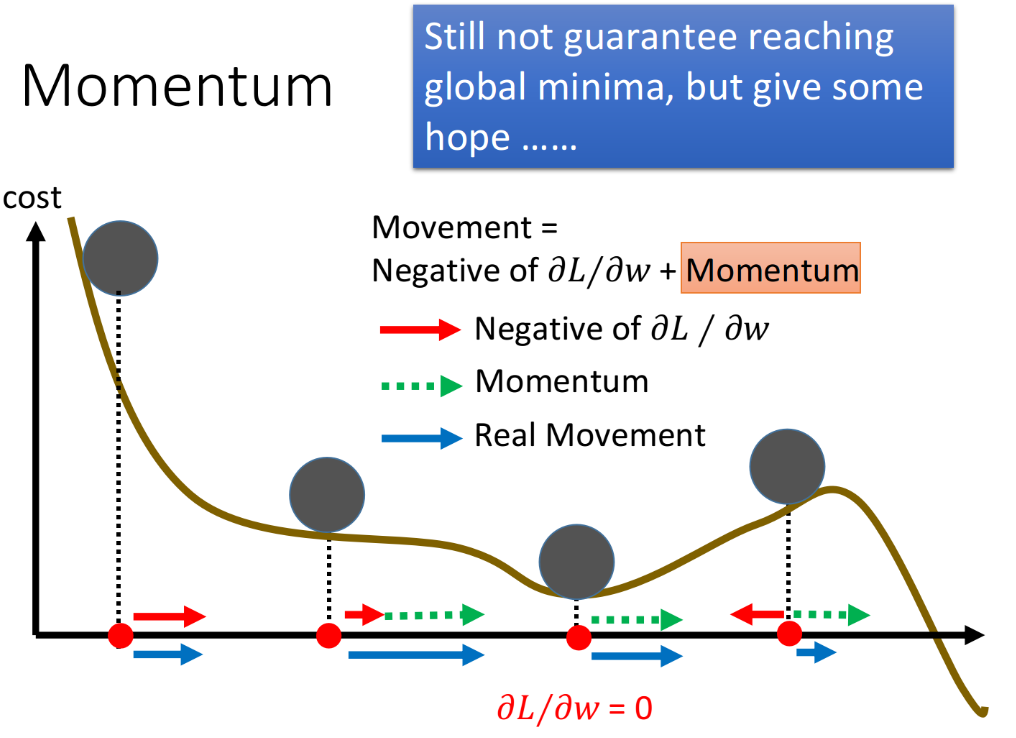
如果我们今天走到local minimum的地方,此时gradient是0,但是Momentum,它指向右侧就是告诉你之前是要走向右边的,所以你仍然应该要继续往右走,所以最后你参数update的方向仍然会继续向右;你甚至可以期待Momentum比较强,惯性的力量可以支撑着你走出这个谷底,去到loss更低的地方。
2.2.4. Adam
RMSProp加上Momentum,就是Adam。根据下面的paper来快速描述一下Adam的algorithm:
先初始化$m_0=0$,$m_0$就是Momentum中,前一个时间点的movement
再初始化$v_0=0$,$v_0$就是RMSProp里计算gradient的root mean square的$\sigma$
最后初始化$t=0$,t用来表示时间点
先算出gradient $g_t$
再根据过去要走的方向$m_{t-1}$和gradient $g_t$,算出现在要走的方向 $m_t$——Momentum
然后根据前一个时间点的$v_{t-1}$和gradient $g_t$的平方,算一下放在分母的$v_t$——RMSProp
接下来做了一个原来RMSProp和Momentum里没有的东西,就是bias correction,它使$m_t$和$v_t$都除上一个值,这个值本来比较小,后来会越来越接近于1 (原理详见paper)
最后做update,把Momentum建议你的方向$\hat{m_t}$乘上learning rate $\alpha$,再除掉RMSProp normalize后建议的learning rate分母,然后得到update的方向

到这里我们就了解了改善Deep learning在training data上的表现的基本方法。下面来介绍如何改善Deep learning在testing data上的表现。
3. Good Results on Testing Data?
在Testing data上得到更好的performance的基本方法,大致可以分为三种:Early Stopping、Regularization和Dropout。值得注意的是,Early Stopping和Regularization是很typical的做法,它们不是特别为deep learning所设计的;而Dropout是一个蛮有deep learning特色的做法。
3.1. Early Stopping
假设你今天的learning rate调的比较好,那随着训练的进行,total loss通常会越来越小,但是Training set和Testing set的情况并不是完全一样的,很有可能当你在Training set上的loss逐渐减小的时候,在Testing set上的loss反而上升了。理想上假如我们知道testing data上的loss变化情况,就会在testing set的loss最小的时候停下来,即提前停止训练—Early Stopping,而不是在training set的loss最小的时候停下来;但testing set实际上是未知的东西,所以我们需要用validation set来替代它去做这件事情。
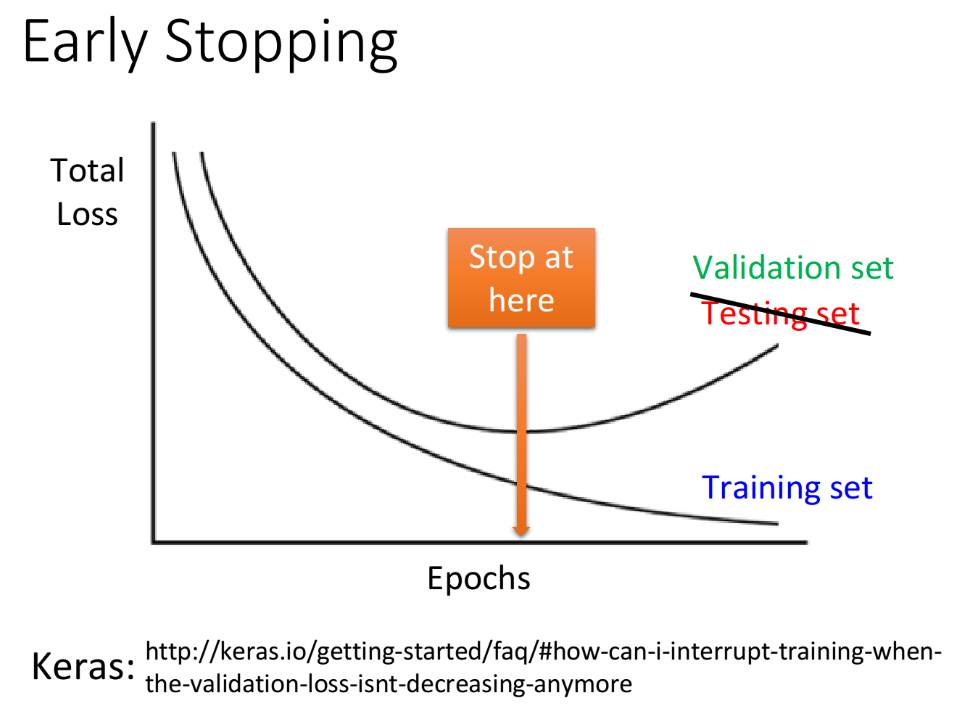
注:很多时候,我们所讲的“testing set”并不是指代那个未知的数据集,而是一些已知的被你拿来做测试之用的数据集,比如kaggle上的public set,或者是你自己切出来的validation set。
3.2. Regularization
regularization就是在原来的loss function上额外增加几个term,比如我们要minimize的loss function原先应该是square error或cross entropy,那在做Regularization的时候,就在后面加一个Regularization的term。
3.2.1. L2 regularization
regularization term可以是参数的L2 norm(L2范数),L2 norm是把model参数集$\theta$里的每一个参数都取平方然后求和,这称作L2 regularization(L2 正则化),即

通常我们在做regularization的时候,新加的term里是不考虑bias这一项的,因为加regularization的目的是为了让我们的function更平滑,而bias通常是跟function的平滑程度没有关系的。
L2 regularization具体流程如下:
- 加上regularization term之后得到了一个新的loss function:$L’(\theta)=L(\theta)+\lambda \frac{1}{2}||\theta||_2$
- 将这个loss function对参数$w_i$求微分:$\frac{\partial L’}{\partial w_i}=\frac{\partial L}{\partial w_i}+\lambda w_i$
- 然后update参数$w_i$:$w_i^{t+1}=w_i^t-\eta \frac{\partial L’}{\partial w_i}=w_i^t-\eta(\frac{\partial L}{\partial w_i}+\lambda w_i^t)=(1-\eta \lambda)w_i^t-\eta \frac{\partial L}{\partial w_i}$

如果把这个推导出来的式子和原式作比较,你会发现参数$w_i$在每次update之前,都会乘上一个$(1-\eta \lambda)$,而$\eta$和$\lambda$通常会被设为一个很小的值,因此$(1-\eta \lambda)$通常是一个接近于1的值,比如0.99,;也就是说,regularization做的事情是,每次update参数$w_i$之前,就先对原来的$w_i$乘个小于1的数,这意味着,随着update次数增加,参数$w_i$会越来越接近于0。
Q:你可能会问,要是所有的参数都越来越靠近0,那最后岂不是$w_i$通通变成0,得到的network还有什么用?
A:其实不会出现最后所有参数都变为0的情况,因为通过微分得到的$\eta \frac{\partial L}{\partial w_i}$这一项是会和前面$(1-\eta \lambda)w_i^t$这一项最后取得平衡的。
使用L2 regularization可以让weight每次都变得更小一点,这就叫做Weight Decay(权重衰减),意思就是如果有一些weight它每次都会越来越小,最后就接近0然后不见了。
3.2.2. L1 regularization
除了L2 regularization中使用平方项作为new term之外,还可以使用L1 regularization,把平方项换成每一个参数的绝对值,即
Q:绝对值不能微分啊,该怎么处理呢?
A:实际上绝对值就是一个V字形的函数,在V的左边微分值是-1,在V的右边微分值是1,只有在0的地方是不能微分的,那在0处就可以设定一个微分值,比如0。
如果w是正的,那微分出来就是+1,如果w是负的,那微分出来就是-1,所以这边用了一个$w$的sign function,它的意思是,如果w是正数的话,这个function output就是+1,w是负数的话,这个function output就是-1。
L1 regularization的流程如下:
- 加上regularization term之后得到了一个新的loss function:$L’(\theta)=L(\theta)+\lambda \frac{1}{2}||\theta||_1$
- 将这个loss function对参数$w_i$求微分:$\frac{\partial L’}{\partial w_i}=\frac{\partial L}{\partial w_i}+\lambda \ sgn(w_i)$
- 然后update参数$w_i$:$w_i^{t+1}=w_i^t-\eta \frac{\partial L’}{\partial w_i}=w_i^t-\eta(\frac{\partial L}{\partial w_i}+\lambda \ sgn(w_i^t))=w_i^t-\eta \frac{\partial L}{\partial w_i}-\eta \lambda \ sgn(w_i^t)$

这个式子告诉我们,每次update参数的时候,都要减去一个$\eta \lambda \ sgn(w_i^t)$,如果w是正的,sgn是+1,就会变成减一个positive的值让你的参数变小;如果w是负的,sgn是-1,就会变成加一个值让你的参数变大;总之就是让它们的绝对值减小至接近于0。
3.2.3. L1 V.s. L2
来对比一下L1和L2的update过程:
L1和L2,虽然它们同样是让参数的绝对值变小,但它们做的事情其实略有不同:
- L1使参数绝对值变小的方式是每次update减掉一个固定的值
- L2使参数绝对值变小的方式是每次update乘上一个小于1的固定值
因此,当参数w的绝对值比较大的时候,L2会让w下降得更快,而L1每次update只让w减去一个固定的值,train完以后可能还会有很多比较大的参数;当参数w的绝对值比较小的时候,L2的下降速度就会变得很慢,train出来的参数平均都是比较小的,而L1每次下降一个固定的value,train出来的参数是比较sparse的,这些参数有很多是接近0的值,也会有很大的值。在之前所讲的CNN的task里,用L1做出来的效果是比较合适的,是比较sparse的。
some tips
ps:在deep learning里面,regularization虽然有帮助,但它的重要性往往没有在SVM这类方法的作用来得高,因为我们在做neural network的时候,通常都是从一个很小的、接近于0的值开始初始参数的,而做update的时候,通常都是让参数离0越来越远,但是regularization要达到的目的,就是希望我们的参数不要离0太远。
如果你做的是Early Stopping,它会减少update的次数,其实也会避免你的参数离0太远,这跟regularization做的事情是很接近的。所以在neural network里面,regularization的作用并没有在SVM来的重要,SVM其实是explicitly把regularization这件事情写在了它的objective function(目标函数)里面,SVM是要去解一个convex optimization problem,因此它解的时候不一定会有iteration的过程,它不会有Early Stopping这件事,而是一步就可以走到那个最好的结果了,所以你没有办法用Early Stopping防止它离目标太远,必须要把regularization explicitly加到loss function里面去。
3.3. Dropout
我们先来介绍dropout是怎么做的,然后再来解释为什么这样做。
3.3.1 How to do Dropout
Training
在training的时候,每次update参数之前,我们对每一个neuron(也包括input layer的“neuron”)做sampling(抽样) ,每个neuron都有p%的几率会被丢掉,如果某个neuron被丢掉的话,跟它相连的weight也都要被丢掉,实际上就是每次update参数之前都通过抽样只保留network中的一部分neuron来做训练。做完sampling以后,network structure就会变得比较细长了,然后再去train这个细长的network。
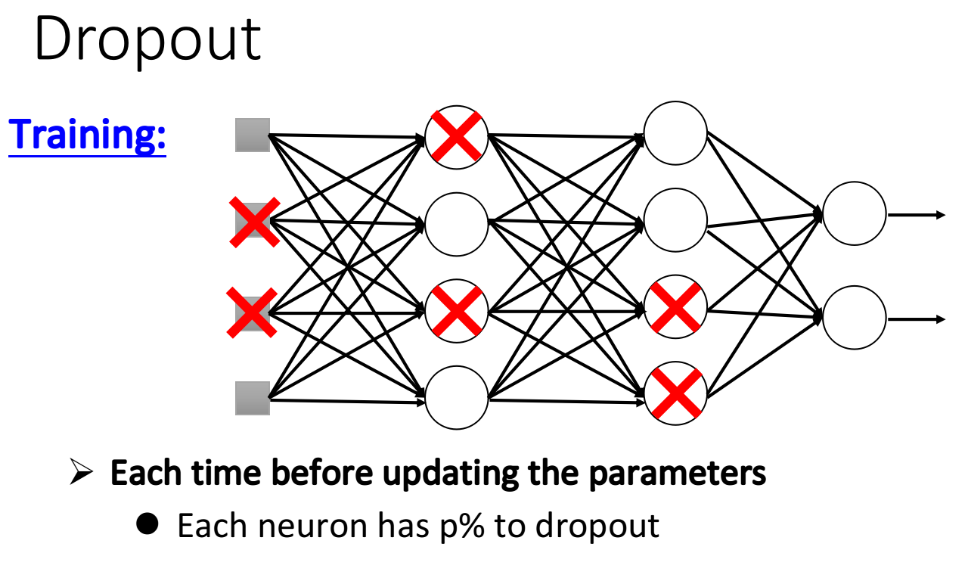
注:每次update参数之前都要做一遍sampling,所以每次update参数的时候,拿来training的network structure都是不一样的;你可能会觉得这个方法跟前面提到的Maxout会有一点像,但实际上,Maxout是每一笔data对应的network structure不同,而Dropout是每一次update参数时(每一个minibatch)的network structure都是不同的。
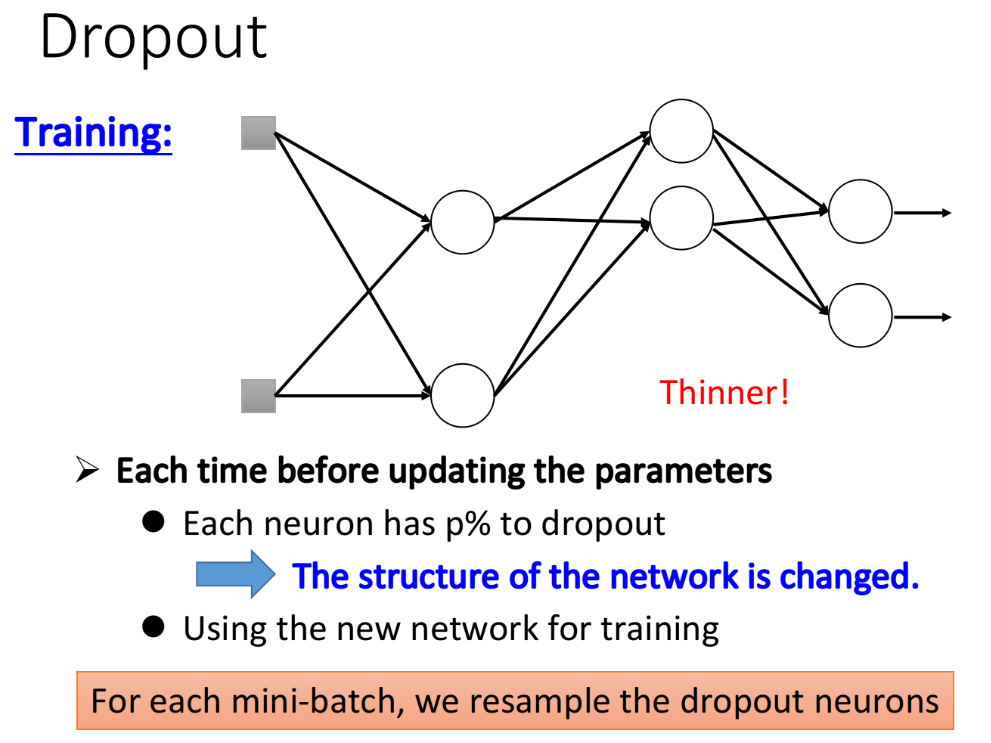
当你在training的时候使用dropout,得到的performance其实是会变差的,因为某些neuron在training的时候莫名其妙就会消失不见,但这并不是问题,因为:
Dropout真正要做的事情,就是要让你在training set上的结果变差,但是在testing set上的结果是变好的。
所以如果你遇到的问题是在training set上得到的performance不够好,你再加dropout,就只会越做越差;我们应该要懂得,不同的problem需要用不同的方法去解决,而不是胡乱使用,dropout就是针对testing set的方法,当然不能够拿来解决training set上的问题。
Testing
在使用dropout方法做testing的时候要注意两件事情:
- testing的时候不做dropout,所有的neuron都要被用到;
- 假设在training的时候,dropout rate是p%,从training data中被learn出来的所有weight都要乘上(1-p%)才能被当做testing的weight使用。
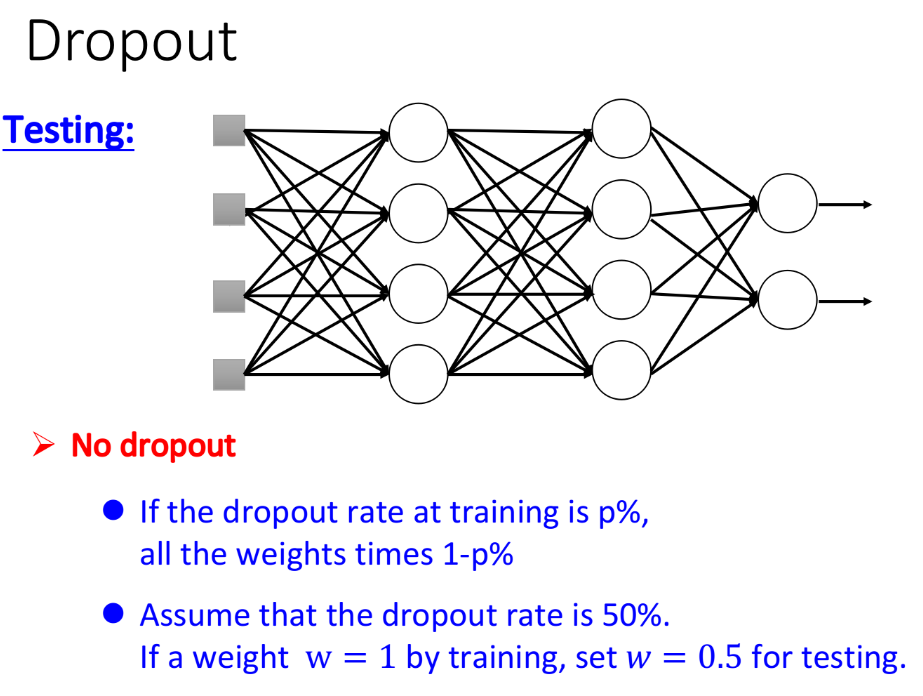
3.3.2. Why Dropout?
为什么dropout会有用?
直觉的想法是:在training的时候,会丢掉一些neuron,就好像是你要练轻功的时候,会在脚上绑一些重物;然后,你在实际战斗的时候,就是实际testing的时候,是没有dropout的,就相当于把重物拿下来,所以你就会变得很强(老火影忍者了)。

另一个直觉的想法是:neural network里面的每一个neuron就是一个学生,那大家被连接在一起就好像要组队做final project,总是有人会拖后腿,就是他会dropout,所以假设你觉得自己的队友会dropout,这个时候你就会想要好好做,然后去carry这个队友,这就是training的过程。那实际在testing的时候,其实大家都有好好做,没有人需要被carry,由于每个人都比一般情况下更努力,所以得到的结果会是更好的,这也就是testing的时候不做dropout的原因。
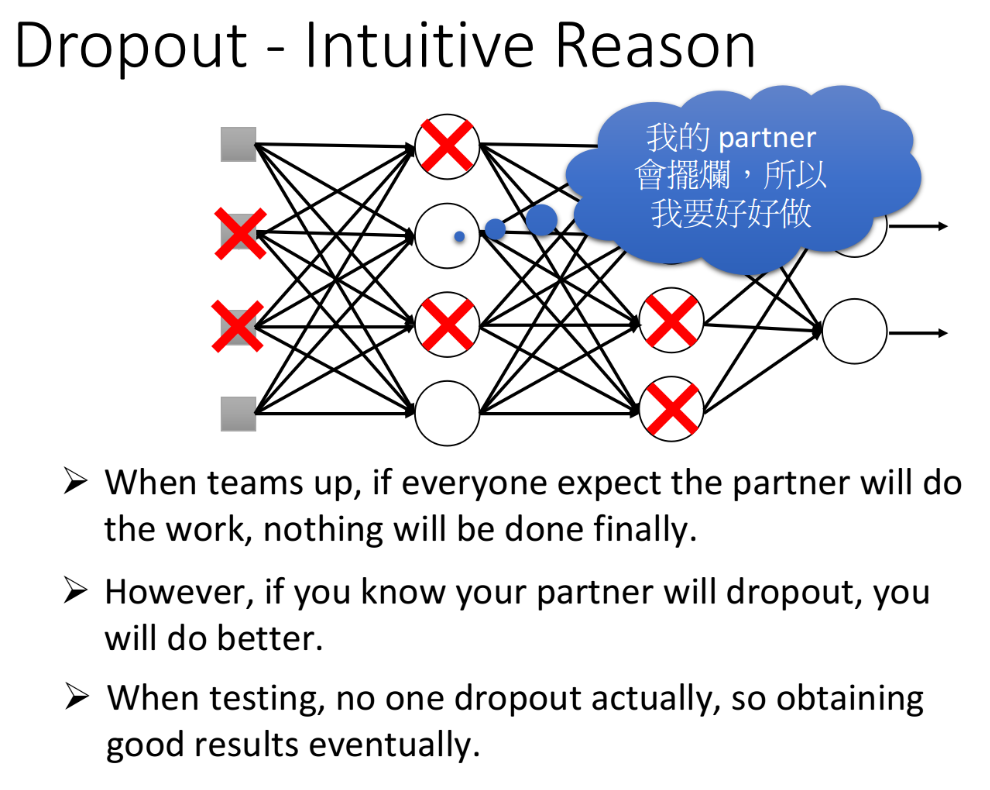
为什么training和testing使用的weight是不一样的呢?
直觉的解释是这样的:假设现在的dropout rate是50%,那在training的时候,你总是期望每次update之前会丢掉一半的neuron,就像下图左侧所示,在这种情况下你learn好了一组weight参数,然后拿去testing。但是在testing的时候是没有dropout的,所以如果testing使用的是和training同一组weight,那左侧得到的output z和右侧得到的output z‘,它们的值其实是会相差两倍的,即$z’≈2z$,这样会造成testing的结果与training的结果并不match,最终的performance反而会变差。这时就需要把右侧testing中所有的weight乘上0.5,然后做normalization,这样z就会等于z’,使得testing的结果与training的结果是比较match的。

Dropout is a kind of ensemble
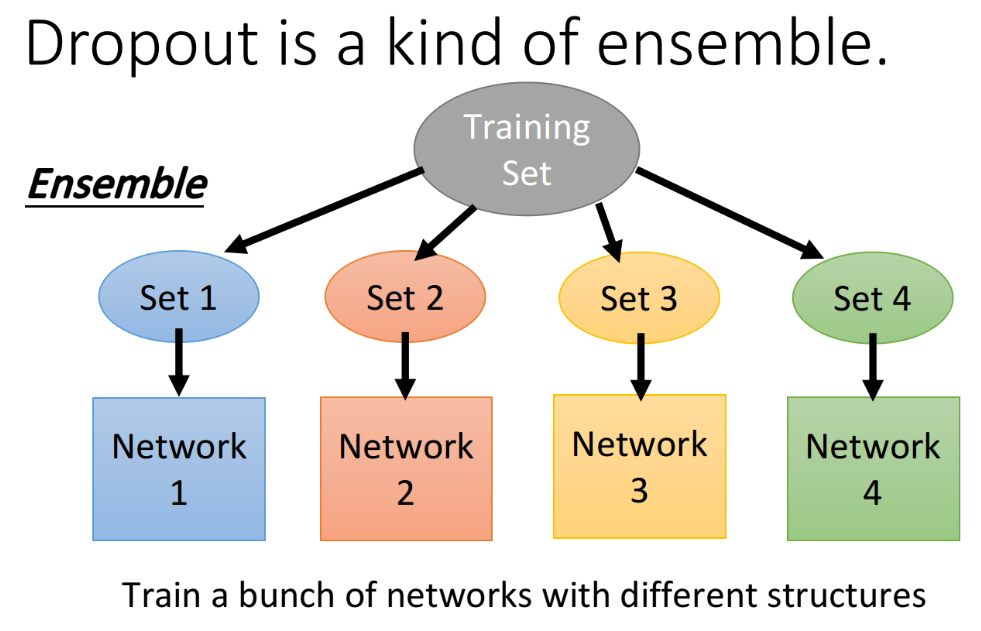
在文献上有很多不同的观点来解释为什么dropout会work,其中一种比较令人信服的解释是:dropout是一种终极的ensemble(集成)的方法。ensemble的方法在比赛的时候经常用得到,它的思想是,我们有一个很大的training set,那你每次都只从这个training set里面sample一部分的data出来,像下图一样,抽取了set1,set2,set3,set4。
我们之前在讲bias和variance的trade off的时候说过,打靶有两种情况:
- 一种是因为bias大而导致打不准(参数过少)
- 另一种是因为variance大而导致打不准(参数过多)
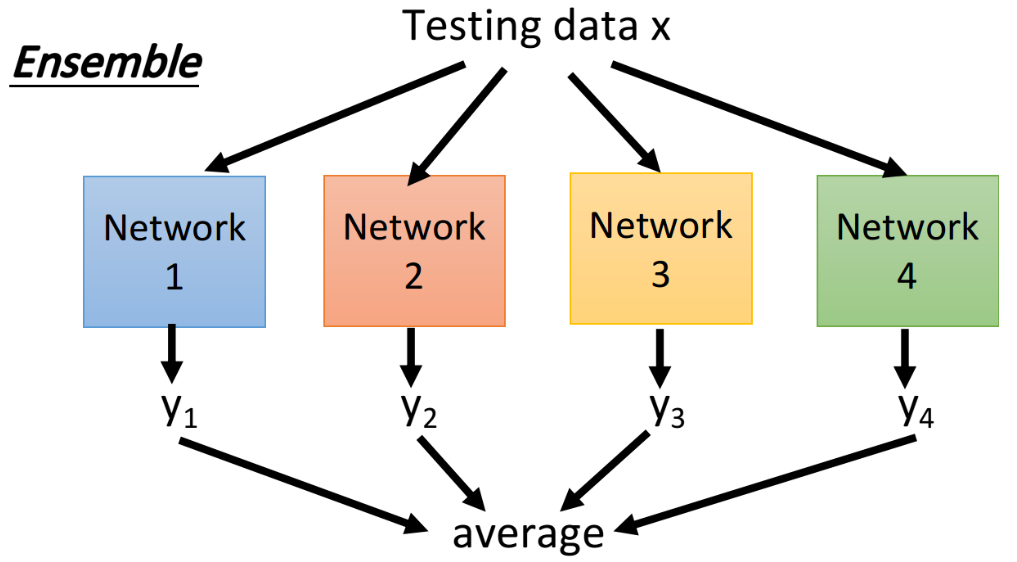
假设我们今天有一个很复杂的model,它往往是bias比较准,但variance很大的情况,如果你有很多个笨重复杂的model,虽然它们的variance都很大,但取平均后,结果往往就会很准。所以ensemble做的事情,就是利用这个特性,我们从原来的training data里面sample出很多subset,然后train很多个model,每一个model的structure甚至都可以不一样;在testing的时候,丢了一笔testing data进来,使它通过所有的model,分别得到结果,然后把这些结果平均起来当做最后的output。
如果你的model很复杂,这一招往往是很有用的。random forest(随机森林)也是实践这种思想的一个方法,也就是如果用一个decision tree,它的效果会很弱,也很容易overfitting,而如果采用random forest,它就没有那么容易overfitting。
为什么dropout是一个终极的ensemble方法呢?
在training network的时候,每次拿一个minibatch出来就做一次update,而根据dropout的特性,每次update之前都要对所有的neuron进行sample,因此每一个minibatch所训练的network structure都是不同的。
假设我们有M个neuron,每个neuron都有可能drop或不drop,所以总共可能的network数量有$2^M$个;所以当你在做dropout的时候,相当于是在用很多个minibatch分别去训练很多个network(一个minibatch一般设置为100笔data),当做了有限次的update之后,就相当于train了很多种不同的network,最多可以训练到$2^M$个network。
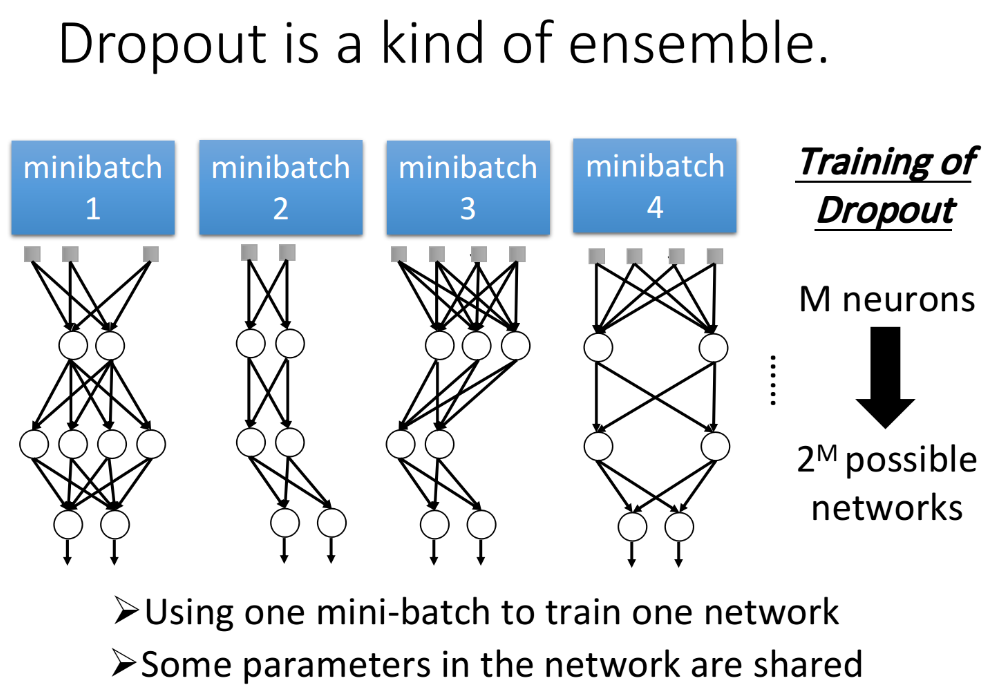
每个network都只用一个minibatch的data来train,可能会让人感到不安,一个batch才100笔data,怎么train一个network呢?其实没有关系,因为这些不同的network之间的参数是shared,也就是说,虽然一个network只能用一个minibatch来train,但同一个weight可以在不同的network里被不同的minibatch train,所以同一个weight实际上是被所有没有丢掉它的network一起share的,它是拿所有这些network的minibatch合起来一起train的结果。
如果按照这个思路来实际操作会遇到这样的问题:我们train出来的network实在太多了,没有办法每一个network都丢一个input进去,再把它们的output平均起来,这样运算量太大了。
那dropout最神奇的地方就在于,它没有把这些network分开考虑,而是用一个完整的network,这个network的weight是用之前那一把network train出来的对应weight乘上(1-p%),然后再把手上这笔testing data丢进这个完整的network,得到的output跟network分开考虑的ensemble的output,是惊人的相近。也就是说下图左侧ensemble的做法和右侧dropout的做法,得到的结果是approximate(近似)的。
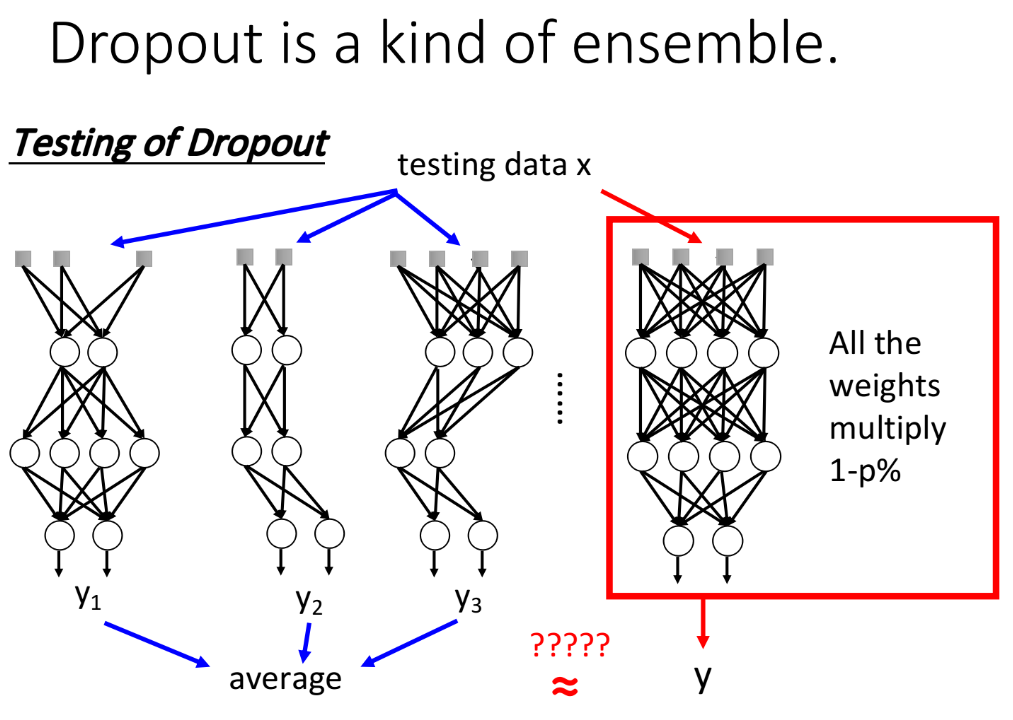
举例说明dropout和ensemble的关系
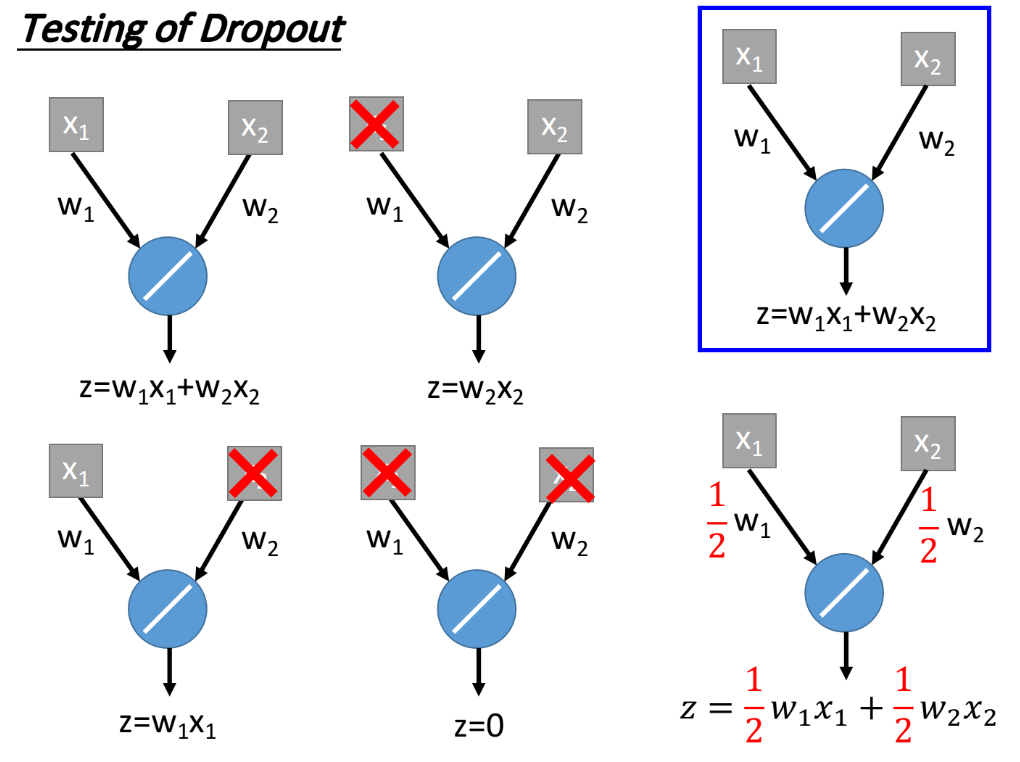
这里用一个例子来解释:我们train一个下图右上角所示的简单的network,它只有一个neuron,activation function是linear的,并且不考虑bias,这个network经过dropout训练以后得到的参数分别为$w_1,w_2$,那给它input $x_1,x_2$,得到的output就是$z=w_1 x_1+w_2 x_2$
如果我们今天要做ensemble的话,theoretically就是像下图这么做,每一个neuron都有可能被drop或不drop,这里只有两个input的neuron,所以我们一共可以得到2^2=4种network。我们把手上这笔testing data $x_1,x_2$丢到这四个network中,分别得到4个output:$w_1x_1+w_2x_2,w_2x_2,w_1x_1,0$,然后根据ensemble的思路,把这四个network的output相加然后取平均,得到的结果是$\frac{1}{2}(w_1x_1+w_2x_2)$。
那根据dropout的想法,我们把从training中得到的参数$w_1,w_2$乘上(1-50%),作为testing network里的参数,也就是$w’_1,w’_2=(1-50\%)(w_1,w_2)=0.5w_1,0.5w_2$。那可以发现,在这个最简单的case里面,用不同的network structure做ensemble这件事情,跟我们用一整个network,并且把weight乘上一个值而不做ensemble所得到的output,其实是一样的。
值得注意的是,只有是linear的network,才会得到上述的等价关系,如果network是非linear的,ensemble和dropout是不equivalent的;但是,dropout最后一个很神奇的地方是,虽然在non-linear的情况下,它是跟ensemble不相等的,但最后的结果还是会work,会很接近。
如果network很接近linear的话,dropout所得到的performance会比较好,而ReLU和Maxout的network相对来说是比较接近于linear的,所以我们通常会把含有ReLU或Maxout的network与Dropout配合起来使用。